Introspective Diffusion Language Models
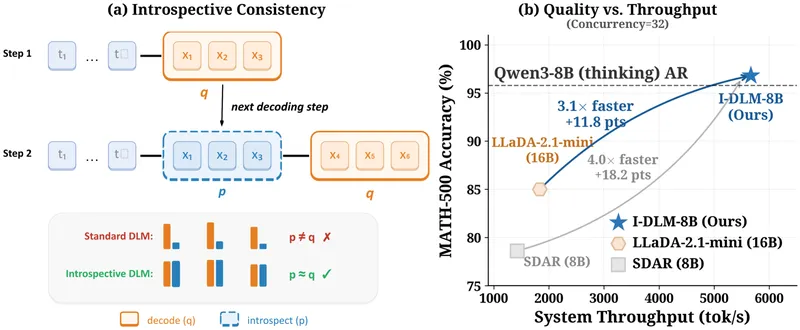
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026

Speculative Speculative Decoding (SSD)
Speculative decoding accelerates autoregressive inference by using a fast draft model to predict upcoming tokens from a slower target model. It verifies predictions in parallel with a single forward pass of the target model, addressing the sequential dependency bottleneck.
arxiv.org
2 min
3/4/2026
Introspective Diffusion Language Models
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026
Speculative Speculative Decoding (SSD)
Speculative decoding accelerates autoregressive inference by using a fast draft model to predict upcoming tokens from a slower target model. It verifies predictions in parallel with a single forward pass of the target model, addressing the sequential dependency bottleneck.
arxiv.org
2 min
3/4/2026
Introspective Diffusion Language Models
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026
Speculative Speculative Decoding (SSD)
Speculative decoding accelerates autoregressive inference by using a fast draft model to predict upcoming tokens from a slower target model. It verifies predictions in parallel with a single forward pass of the target model, addressing the sequential dependency bottleneck.
arxiv.org
2 min
3/4/2026
No more articles to load