
DiffusionGemma: 4x Faster Text Generation
DiffusionGemma is a 26B Mixture of Experts (MoE) model that utilizes text diffusion for text generation. It can generate entire blocks of text simultaneously, achieving up to 4x faster performance on GPUs compared to traditional autoregressive Large Language Models.
blog.google
5 min
6/10/2026

1-Bit Bonsai Image 4B Image Generation for Local Devices
Bonsai Image 4B is a family of compact image-generation models designed for high-quality diffusion inference on local devices, including laptops and phones. The 1-bit variant utilizes binary transformer weights with an FP16 scaling factor, achieving maximum compression with 1.125 effective bits per weight.
prismml.com
6 min
5/31/2026
Learning the Integral of a Diffusion Model
Sampling from a diffusion model involves an iterative process where a denoiser estimates the tangent direction to a path through input space. Neural networks can be trained to directly predict the integral that transforms samples from a simple noise distribution into samples from a target distribution.
sander.ai
83 min
5/6/2026
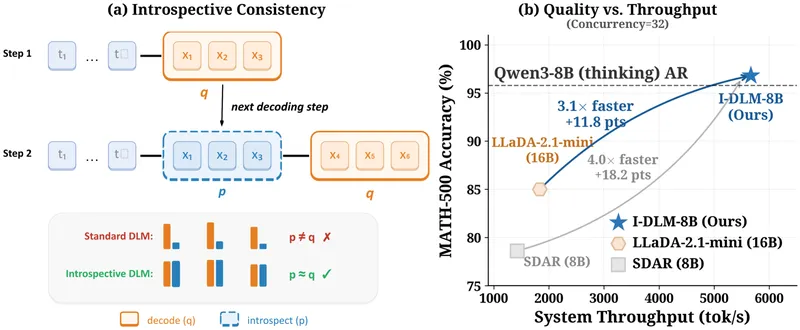
Introspective Diffusion Language Models
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
DiffusionGemma: 4x Faster Text Generation
DiffusionGemma is a 26B Mixture of Experts (MoE) model that utilizes text diffusion for text generation. It can generate entire blocks of text simultaneously, achieving up to 4x faster performance on GPUs compared to traditional autoregressive Large Language Models.
blog.google
5 min
6/10/2026
Learning the Integral of a Diffusion Model
Sampling from a diffusion model involves an iterative process where a denoiser estimates the tangent direction to a path through input space. Neural networks can be trained to directly predict the integral that transforms samples from a simple noise distribution into samples from a target distribution.
sander.ai
83 min
5/6/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
1-Bit Bonsai Image 4B Image Generation for Local Devices
Bonsai Image 4B is a family of compact image-generation models designed for high-quality diffusion inference on local devices, including laptops and phones. The 1-bit variant utilizes binary transformer weights with an FP16 scaling factor, achieving maximum compression with 1.125 effective bits per weight.
prismml.com
6 min
5/31/2026
Introspective Diffusion Language Models
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026
DiffusionGemma: 4x Faster Text Generation
DiffusionGemma is a 26B Mixture of Experts (MoE) model that utilizes text diffusion for text generation. It can generate entire blocks of text simultaneously, achieving up to 4x faster performance on GPUs compared to traditional autoregressive Large Language Models.
blog.google
5 min
6/10/2026
Introspective Diffusion Language Models
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
introspective-diffusion.github.io
4 min
4/14/2026
1-Bit Bonsai Image 4B Image Generation for Local Devices
Bonsai Image 4B is a family of compact image-generation models designed for high-quality diffusion inference on local devices, including laptops and phones. The 1-bit variant utilizes binary transformer weights with an FP16 scaling factor, achieving maximum compression with 1.125 effective bits per weight.
prismml.com
6 min
5/31/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
Learning the Integral of a Diffusion Model
Sampling from a diffusion model involves an iterative process where a denoiser estimates the tangent direction to a path through input space. Neural networks can be trained to directly predict the integral that transforms samples from a simple noise distribution into samples from a target distribution.
sander.ai
83 min
5/6/2026
No more articles to load