
Rio de Janeiro's "homegrown" LLM appears to be a merge of an existing model
Rio-3.5-Open-397B is a 397B model that combines weights from Nex-N2_pro and Qwen3.5-397B-A17B in a ratio of 0.6 to 0.4. There is no evidence of independent training for this model, indicating it is a direct merge of existing models.
github.com
1 min
6/14/2026

RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026
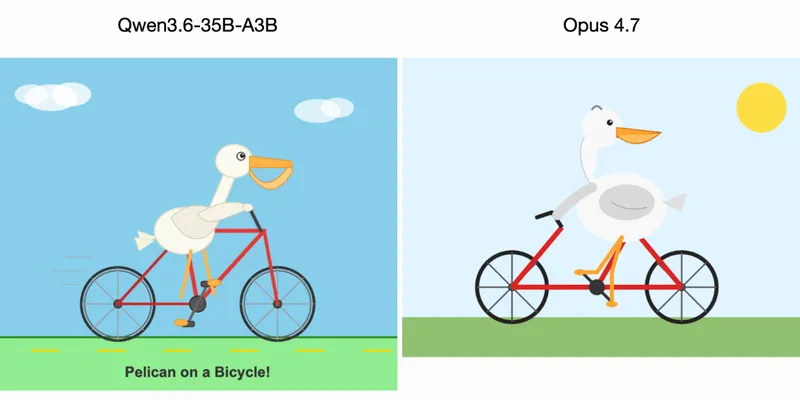
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
Qwen3.6-35B-A3B generated a superior image of a pelican compared to Claude Opus 4.7. The Qwen model was run on a MacBook Pro M5 using LM Studio.
simonwillison.net
2 min
4/16/2026

Qwen3.6-Plus: Towards real world agents
Qwen Chat provides extensive capabilities, including chatbot functionality, image and video comprehension, image generation, document processing, web search integration, and tool utilization. The platform also supports the handling of various artifacts.
qwen.ai
1 min
4/2/2026

Something is afoot in the land of Qwen
Alibaba's Qwen team has released the Qwen 3.5 family of open weight models. Junyang Lin, the lead researcher, announced his departure from the team via Twitter.
simonwillison.net
4 min
3/4/2026

Did Alibaba just kneecap its powerful Qwen AI team?
Key figures from Alibaba's Qwen AI team, known for their extensive contributions to open source generative models, have departed following the release of the Qwen3.5 small model series. The release received public acclaim from Elon Musk for its notable intelligence density.
venturebeat.com
5 min
3/4/2026
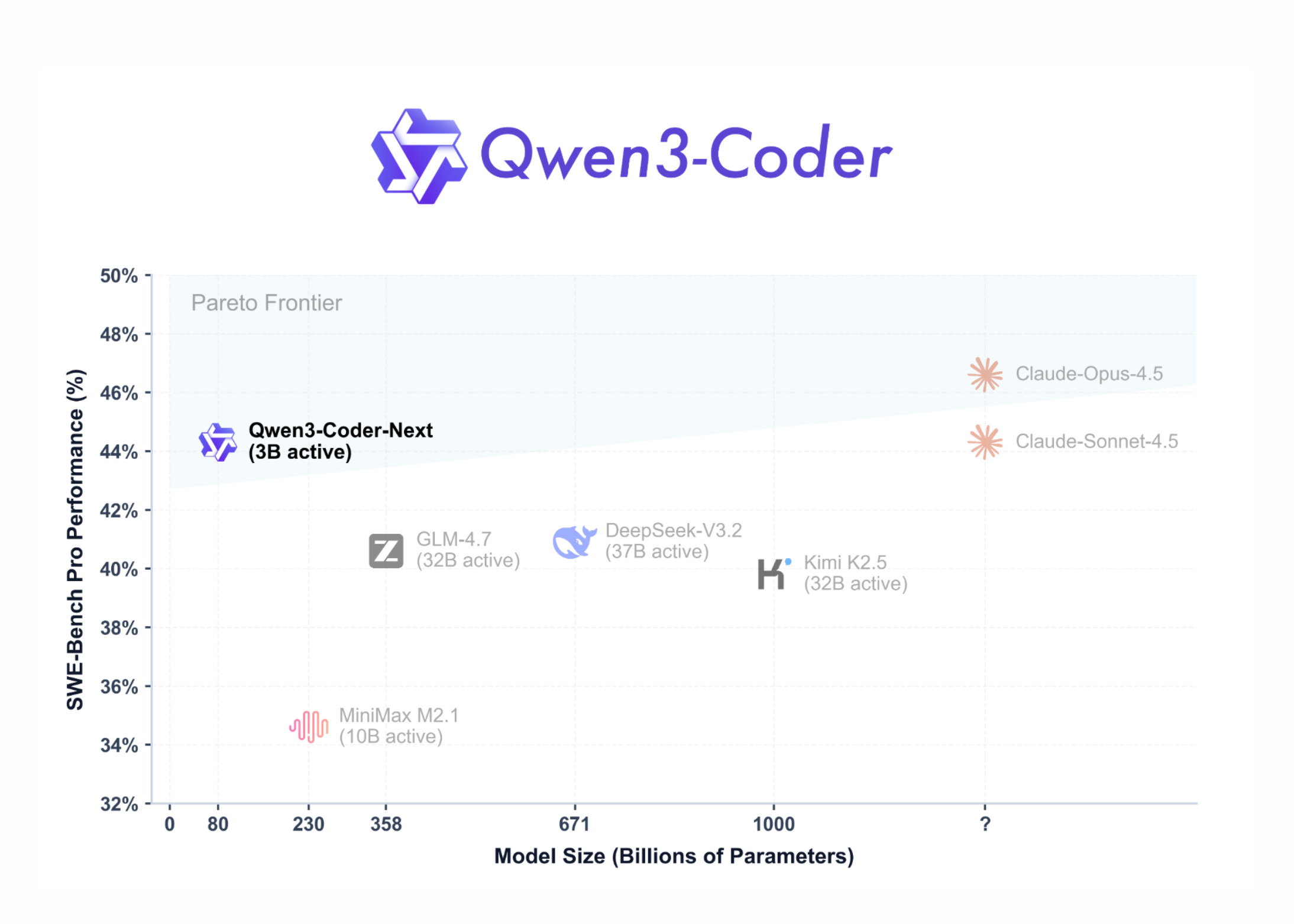
Alibaba releases Qwen3-Coder-Next to rival OpenAI, Anthropic
Qwen3-Coder-Next is an open-weight language model designed for coding agents and local development, built on the Qwen3-Next-80B-A3B backbone. It features a sparse Mixture-of-Experts (MoE) architecture with 80 billion total parameters, activating only 3 billion parameters per token to optimize performance and reduce inference costs.
marktechpost.com
5 min
2/4/2026
Rio de Janeiro's "homegrown" LLM appears to be a merge of an existing model
Rio-3.5-Open-397B is a 397B model that combines weights from Nex-N2_pro and Qwen3.5-397B-A17B in a ratio of 0.6 to 0.4. There is no evidence of independent training for this model, indicating it is a direct merge of existing models.
github.com
1 min
6/14/2026
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
Qwen3.6-35B-A3B generated a superior image of a pelican compared to Claude Opus 4.7. The Qwen model was run on a MacBook Pro M5 using LM Studio.
simonwillison.net
2 min
4/16/2026
Something is afoot in the land of Qwen
Alibaba's Qwen team has released the Qwen 3.5 family of open weight models. Junyang Lin, the lead researcher, announced his departure from the team via Twitter.
simonwillison.net
4 min
3/4/2026
Alibaba releases Qwen3-Coder-Next to rival OpenAI, Anthropic
Qwen3-Coder-Next is an open-weight language model designed for coding agents and local development, built on the Qwen3-Next-80B-A3B backbone. It features a sparse Mixture-of-Experts (MoE) architecture with 80 billion total parameters, activating only 3 billion parameters per token to optimize performance and reduce inference costs.
marktechpost.com
5 min
2/4/2026
RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026
Qwen3.6-Plus: Towards real world agents
Qwen Chat provides extensive capabilities, including chatbot functionality, image and video comprehension, image generation, document processing, web search integration, and tool utilization. The platform also supports the handling of various artifacts.
qwen.ai
1 min
4/2/2026
Did Alibaba just kneecap its powerful Qwen AI team?
Key figures from Alibaba's Qwen AI team, known for their extensive contributions to open source generative models, have departed following the release of the Qwen3.5 small model series. The release received public acclaim from Elon Musk for its notable intelligence density.
venturebeat.com
5 min
3/4/2026
Rio de Janeiro's "homegrown" LLM appears to be a merge of an existing model
Rio-3.5-Open-397B is a 397B model that combines weights from Nex-N2_pro and Qwen3.5-397B-A17B in a ratio of 0.6 to 0.4. There is no evidence of independent training for this model, indicating it is a direct merge of existing models.
github.com
1 min
6/14/2026
Qwen3.6-Plus: Towards real world agents
Qwen Chat provides extensive capabilities, including chatbot functionality, image and video comprehension, image generation, document processing, web search integration, and tool utilization. The platform also supports the handling of various artifacts.
qwen.ai
1 min
4/2/2026
Alibaba releases Qwen3-Coder-Next to rival OpenAI, Anthropic
Qwen3-Coder-Next is an open-weight language model designed for coding agents and local development, built on the Qwen3-Next-80B-A3B backbone. It features a sparse Mixture-of-Experts (MoE) architecture with 80 billion total parameters, activating only 3 billion parameters per token to optimize performance and reduce inference costs.
marktechpost.com
5 min
2/4/2026
RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026
Something is afoot in the land of Qwen
Alibaba's Qwen team has released the Qwen 3.5 family of open weight models. Junyang Lin, the lead researcher, announced his departure from the team via Twitter.
simonwillison.net
4 min
3/4/2026
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
Qwen3.6-35B-A3B generated a superior image of a pelican compared to Claude Opus 4.7. The Qwen model was run on a MacBook Pro M5 using LM Studio.
simonwillison.net
2 min
4/16/2026
Did Alibaba just kneecap its powerful Qwen AI team?
Key figures from Alibaba's Qwen AI team, known for their extensive contributions to open source generative models, have departed following the release of the Qwen3.5 small model series. The release received public acclaim from Elon Musk for its notable intelligence density.
venturebeat.com
5 min
3/4/2026
No more articles to load