
ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
4d ago
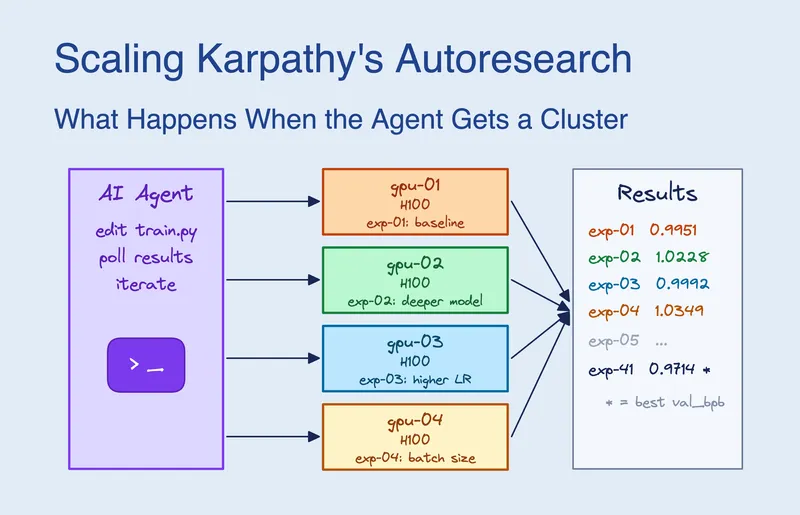
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026

Language Model Teams as Distrbuted Systems
Large language models (LLMs) are being deployed in teams, raising questions about their effectiveness, optimal team size, structural impact on performance, and comparative advantages over individual models. A principled framework is needed to address these key issues in the context of multiagent systems.
arxiv.org
2 min
3/16/2026

Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026

Learning athletic humanoid tennis skills from imperfect human motion data
LATENT enables the simulation of highly-dynamic tennis rallies by human athletes, showcasing versatile skills in a competitive environment. Developed by researchers from Tsinghua University, Peking University, and other institutions, it utilizes advanced AI techniques for real-time performance.
zzk273.github.io
1 min
3/15/2026
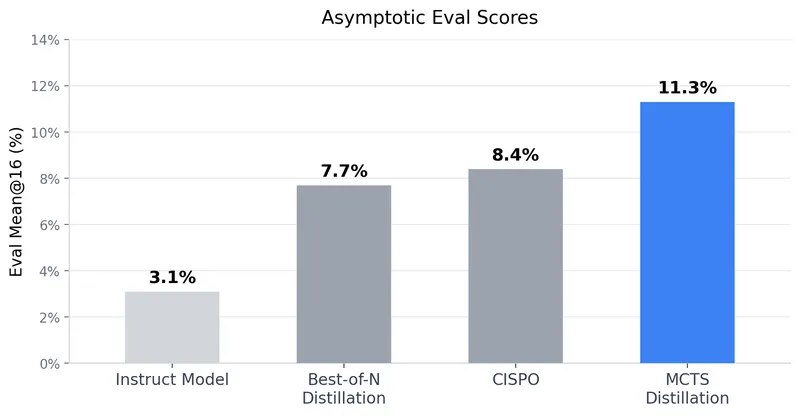
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026

Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026
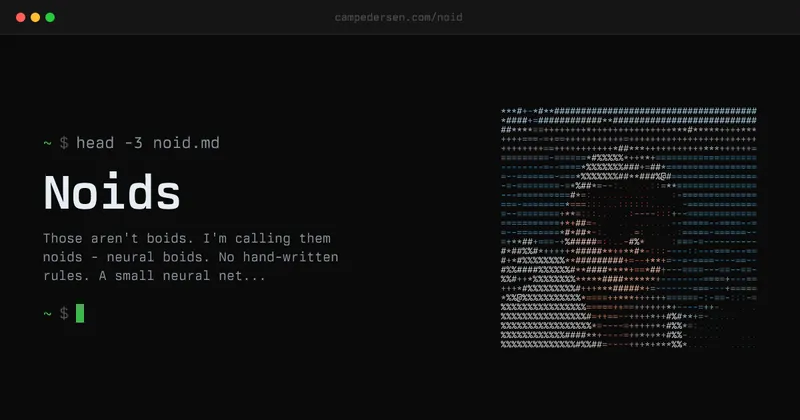
Neural Boids
Noids, or neural boids, utilize a small neural network to generate steering forces based on visual input from each agent, comprising 1,922 learned parameters. This system mimics the behavior of real birds in a murmuration, where no leader or predetermined choreography directs the movement of the flock.
campedersen.com
10 min
3/8/2026

SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026
![Claude's Cycles [pdf]](https://pub-90f0ac00d93c47daac3e1d2cdd28d496.r2.dev/articles/028327bdaffead529e2dd4ca4f598baa.webp)
ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
4d ago
Language Model Teams as Distrbuted Systems
Large language models (LLMs) are being deployed in teams, raising questions about their effectiveness, optimal team size, structural impact on performance, and comparative advantages over individual models. A principled framework is needed to address these key issues in the context of multiagent systems.
arxiv.org
2 min
3/16/2026
Learning athletic humanoid tennis skills from imperfect human motion data
LATENT enables the simulation of highly-dynamic tennis rallies by human athletes, showcasing versatile skills in a competitive environment. Developed by researchers from Tsinghua University, Peking University, and other institutions, it utilizes advanced AI techniques for real-time performance.
zzk273.github.io
1 min
3/15/2026
Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
Neural Boids
Noids, or neural boids, utilize a small neural network to generate steering forces based on visual input from each agent, comprising 1,922 learned parameters. This system mimics the behavior of real birds in a murmuration, where no leader or predetermined choreography directs the movement of the flock.
campedersen.com
10 min
3/8/2026
ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
4d ago
Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026
Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
Learning athletic humanoid tennis skills from imperfect human motion data
LATENT enables the simulation of highly-dynamic tennis rallies by human athletes, showcasing versatile skills in a competitive environment. Developed by researchers from Tsinghua University, Peking University, and other institutions, it utilizes advanced AI techniques for real-time performance.
zzk273.github.io
1 min
3/15/2026
Neural Boids
Noids, or neural boids, utilize a small neural network to generate steering forces based on visual input from each agent, comprising 1,922 learned parameters. This system mimics the behavior of real birds in a murmuration, where no leader or predetermined choreography directs the movement of the flock.
campedersen.com
10 min
3/8/2026
Language Model Teams as Distrbuted Systems
Large language models (LLMs) are being deployed in teams, raising questions about their effectiveness, optimal team size, structural impact on performance, and comparative advantages over individual models. A principled framework is needed to address these key issues in the context of multiagent systems.
arxiv.org
2 min
3/16/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026