
90% of Claude-linked output going to GitHub repos w <2 stars
Claude Code has experienced an 8% week-over-week growth, with a doubling time of 61 days. The earliest observed public-era commits for Claude Code adoption include a change to the initial game setup in the moinmir/ClashOfCans project on February 24, 2025.
claudescode.dev
12 min
4d ago

Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026

Comparing Python Type Checkers: Typing Spec Conformance
Python's type system began with PEP 484, establishing foundational rules for type checking. A comparison of various type checkers reveals differing levels of conformance to the Python typing specification.
pyrefly.org
6 min
3/16/2026

Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026

SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026
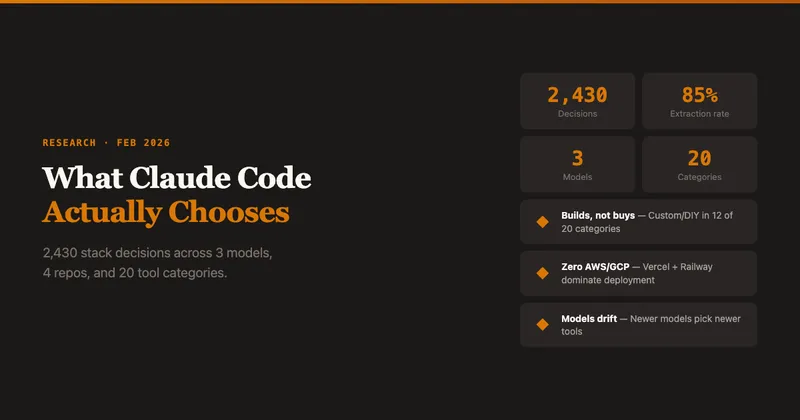
What Claude Code Chooses
Claude Code was tested on real repositories 2,430 times using open-ended questions, achieving an 85.3% extraction rate across three models, four project types, and 20 tool categories. The primary finding indicates that Claude Code favors building custom solutions over purchasing existing tools.
amplifying.ai
3 min
2/26/2026

Ed Zitron loses his mind annotating an AI doomer macro memo
Se compartió con Dropbox.
dropbox.com
1 min
2/25/2026
We are changing our developer productivity experiment design
METR's previous study indicated a 20% slowdown in task completion among experienced open-source developers using AI tools. A new experiment launched in August 2025 aims to assess AI's impact on developer productivity over time, but participant feedback suggests the data may be unreliable.
metr.org
8 min
2/24/2026
We hid backdoors in ~40MB binaries and asked AI + Ghidra to find them
Backdoors were hidden in ~40MB binaries to test AI and Ghidra's capabilities in malware detection. The experiment involved collaboration with Michał “Redford” Kowalczyk, a reverse engineering expert, to establish a benchmark for identifying malicious code in binaries.
quesma.com
14 min
2/22/2026

Consistency diffusion language models: Up to 14x faster, no quality loss
Consistency diffusion language models (CDLM) achieve up to 14.5x faster inference by utilizing consistency-based multi-token finalization and block-wise KV caching. These models provide a viable alternative to autoregressive language models for tasks such as math and coding.
together.ai
11 min
2/20/2026
90% of Claude-linked output going to GitHub repos w <2 stars
Claude Code has experienced an 8% week-over-week growth, with a doubling time of 61 days. The earliest observed public-era commits for Claude Code adoption include a change to the initial game setup in the moinmir/ClashOfCans project on February 24, 2025.
claudescode.dev
12 min
4d ago
Comparing Python Type Checkers: Typing Spec Conformance
Python's type system began with PEP 484, establishing foundational rules for type checking. A comparison of various type checkers reveals differing levels of conformance to the Python typing specification.
pyrefly.org
6 min
3/16/2026
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026
Ed Zitron loses his mind annotating an AI doomer macro memo
Se compartió con Dropbox.
dropbox.com
1 min
2/25/2026
We hid backdoors in ~40MB binaries and asked AI + Ghidra to find them
Backdoors were hidden in ~40MB binaries to test AI and Ghidra's capabilities in malware detection. The experiment involved collaboration with Michał “Redford” Kowalczyk, a reverse engineering expert, to establish a benchmark for identifying malicious code in binaries.
quesma.com
14 min
2/22/2026
Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026
Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026
What Claude Code Chooses
Claude Code was tested on real repositories 2,430 times using open-ended questions, achieving an 85.3% extraction rate across three models, four project types, and 20 tool categories. The primary finding indicates that Claude Code favors building custom solutions over purchasing existing tools.
amplifying.ai
3 min
2/26/2026
We are changing our developer productivity experiment design
METR's previous study indicated a 20% slowdown in task completion among experienced open-source developers using AI tools. A new experiment launched in August 2025 aims to assess AI's impact on developer productivity over time, but participant feedback suggests the data may be unreliable.
metr.org
8 min
2/24/2026
Consistency diffusion language models: Up to 14x faster, no quality loss
Consistency diffusion language models (CDLM) achieve up to 14.5x faster inference by utilizing consistency-based multi-token finalization and block-wise KV caching. These models provide a viable alternative to autoregressive language models for tasks such as math and coding.
together.ai
11 min
2/20/2026
90% of Claude-linked output going to GitHub repos w <2 stars
Claude Code has experienced an 8% week-over-week growth, with a doubling time of 61 days. The earliest observed public-era commits for Claude Code adoption include a change to the initial game setup in the moinmir/ClashOfCans project on February 24, 2025.
claudescode.dev
12 min
4d ago
Many SWE-bench-Passing PRs would not be merged
Approximately 50% of test-passing SWE-bench Verified pull requests created by AI agents between mid-2024 and late-2025 would not be merged into the main branch by repository maintainers. The findings suggest that the lack of iterative feedback for AI agents does not indicate a fundamental capability limitation.
metr.org
18 min
3/11/2026
Ed Zitron loses his mind annotating an AI doomer macro memo
Se compartió con Dropbox.
dropbox.com
1 min
2/25/2026
Consistency diffusion language models: Up to 14x faster, no quality loss
Consistency diffusion language models (CDLM) achieve up to 14.5x faster inference by utilizing consistency-based multi-token finalization and block-wise KV caching. These models provide a viable alternative to autoregressive language models for tasks such as math and coding.
together.ai
11 min
2/20/2026
Speed at the cost of quality: Study of use of Cursor AI in open source projects (2025)
Cursor AI enhances short-term development speed in open-source projects by leveraging large language models (LLMs). However, this acceleration may lead to increased long-term complexity in software maintenance and quality.
arxiv.org
2 min
3/16/2026
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via CI
Large language model-powered agents can automate software engineering tasks, including static bug fixing, as shown by benchmarks like SWE-bench. Real-world software development requires navigating complex requirements beyond these capabilities.
arxiv.org
2 min
3/8/2026
We are changing our developer productivity experiment design
METR's previous study indicated a 20% slowdown in task completion among experienced open-source developers using AI tools. A new experiment launched in August 2025 aims to assess AI's impact on developer productivity over time, but participant feedback suggests the data may be unreliable.
metr.org
8 min
2/24/2026
Comparing Python Type Checkers: Typing Spec Conformance
Python's type system began with PEP 484, establishing foundational rules for type checking. A comparison of various type checkers reveals differing levels of conformance to the Python typing specification.
pyrefly.org
6 min
3/16/2026
What Claude Code Chooses
Claude Code was tested on real repositories 2,430 times using open-ended questions, achieving an 85.3% extraction rate across three models, four project types, and 20 tool categories. The primary finding indicates that Claude Code favors building custom solutions over purchasing existing tools.
amplifying.ai
3 min
2/26/2026
We hid backdoors in ~40MB binaries and asked AI + Ghidra to find them
Backdoors were hidden in ~40MB binaries to test AI and Ghidra's capabilities in malware detection. The experiment involved collaboration with Michał “Redford” Kowalczyk, a reverse engineering expert, to establish a benchmark for identifying malicious code in binaries.
quesma.com
14 min
2/22/2026