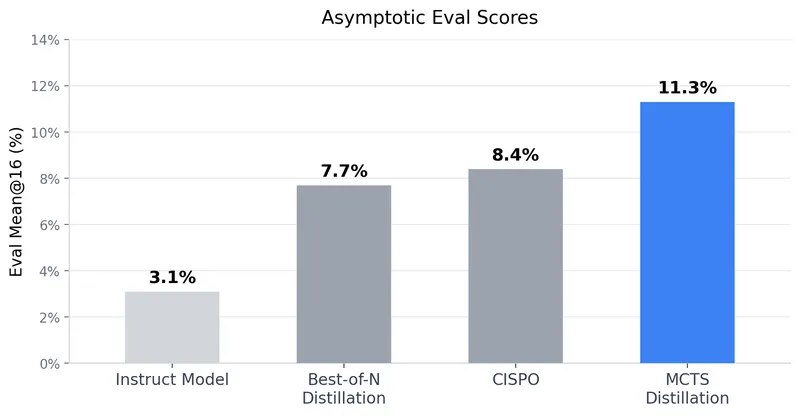
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026

Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026
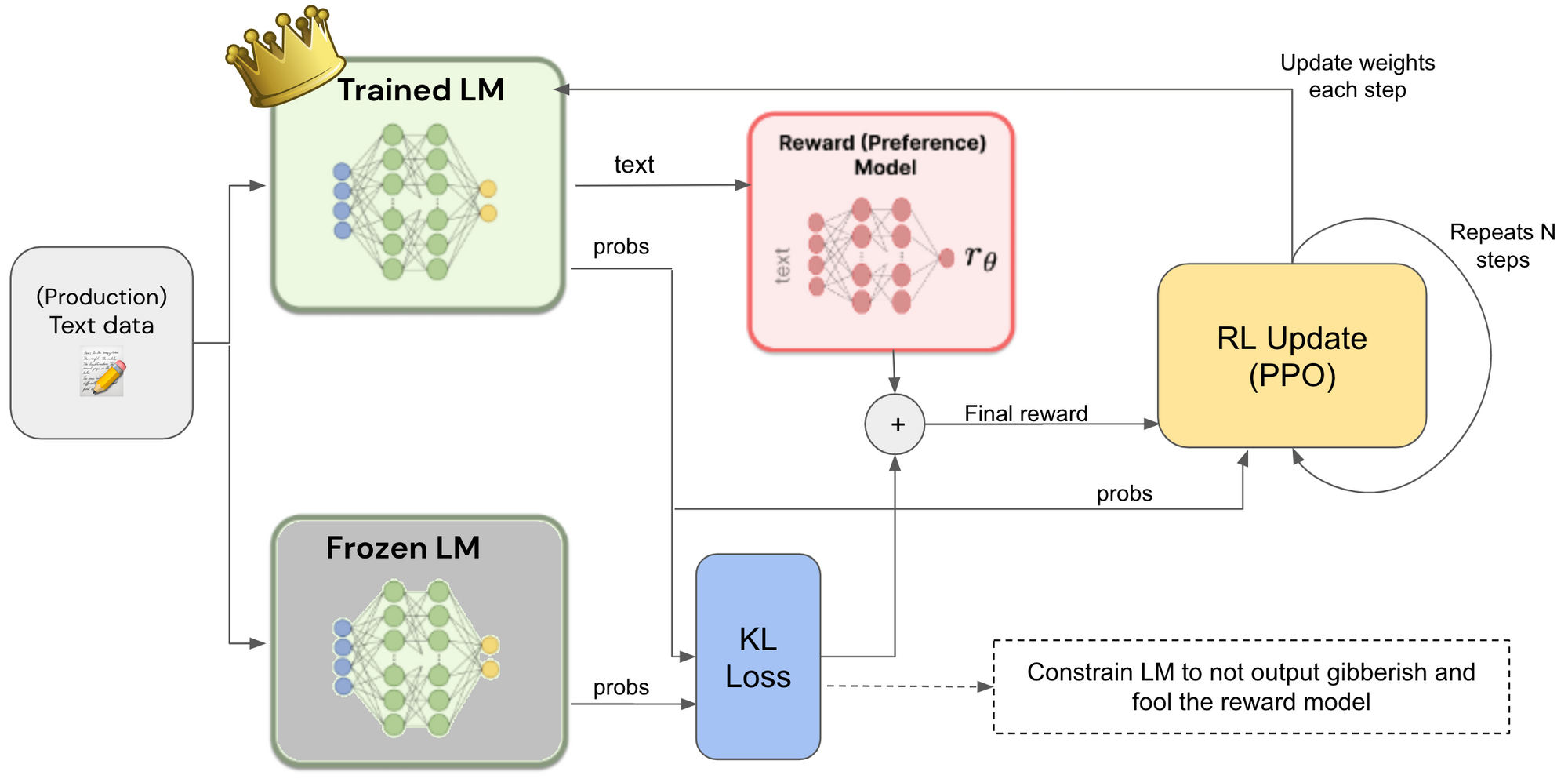
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
No more articles to load