
Maxproof
MaxProof is a framework designed for population-level test-time scaling in mathematical proof, specifically within the MiniMax-M3 series. It trains three key capabilities: proof generation, proof verification, and critique-conditioned proof repair.
arxiv.org
2 min
6/12/2026
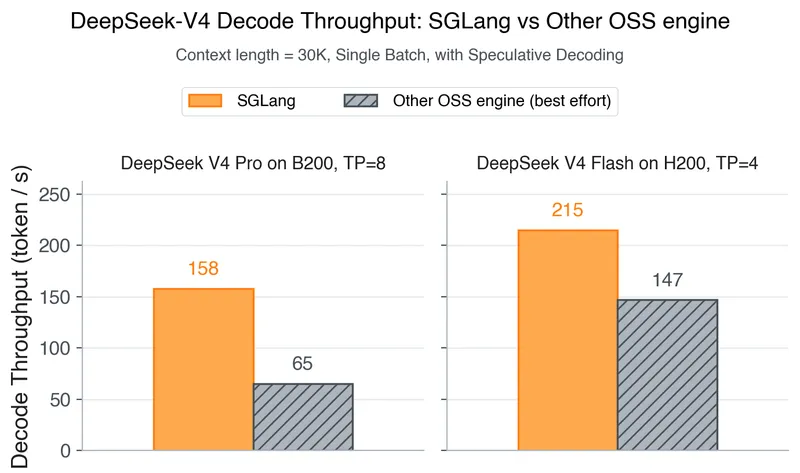
DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
DeepSeek-V4 is now supported for both inference and reinforcement learning (RL) training from Day 0. SGLang and Miles provide the first open-source stack designed for DeepSeek-V4’s hybrid sparse-attention architecture and manifold-constrained hyper-connections, utilizing FP4 expert weights.
lmsys.org
17 min
4/25/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
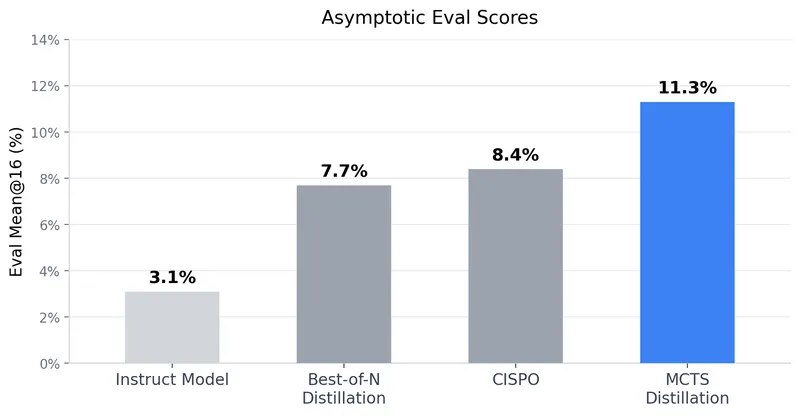
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026

Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026

MiniMax M2.5 released: 80.2% in SWE-bench Verified
MiniMax M2.5 is a state-of-the-art AI model designed for real-world productivity, achieving scores of 80.2% in SWE-Bench Verified, 51.3% in Multi-SWE-Bench, and 76.3% in BrowseComp. It has been extensively trained using reinforcement learning across hundreds of thousands of complex environments, excelling in coding, agentic tool use, search, and office tasks.
minimax.io
13 min
2/12/2026
RLHF from Scratch
The GitHub repository "ashworks1706/rlhf-from-scratch" provides a hands-on tutorial on Reinforcement Learning with Human Feedback (RLHF) and its applications in Large Language Models. It includes a simple Proximal Policy Optimization (PPO) training loop, helper routines for processing and reward computation, and a Jupyter notebook for experimentation.
github.com
1 min
2/11/2026
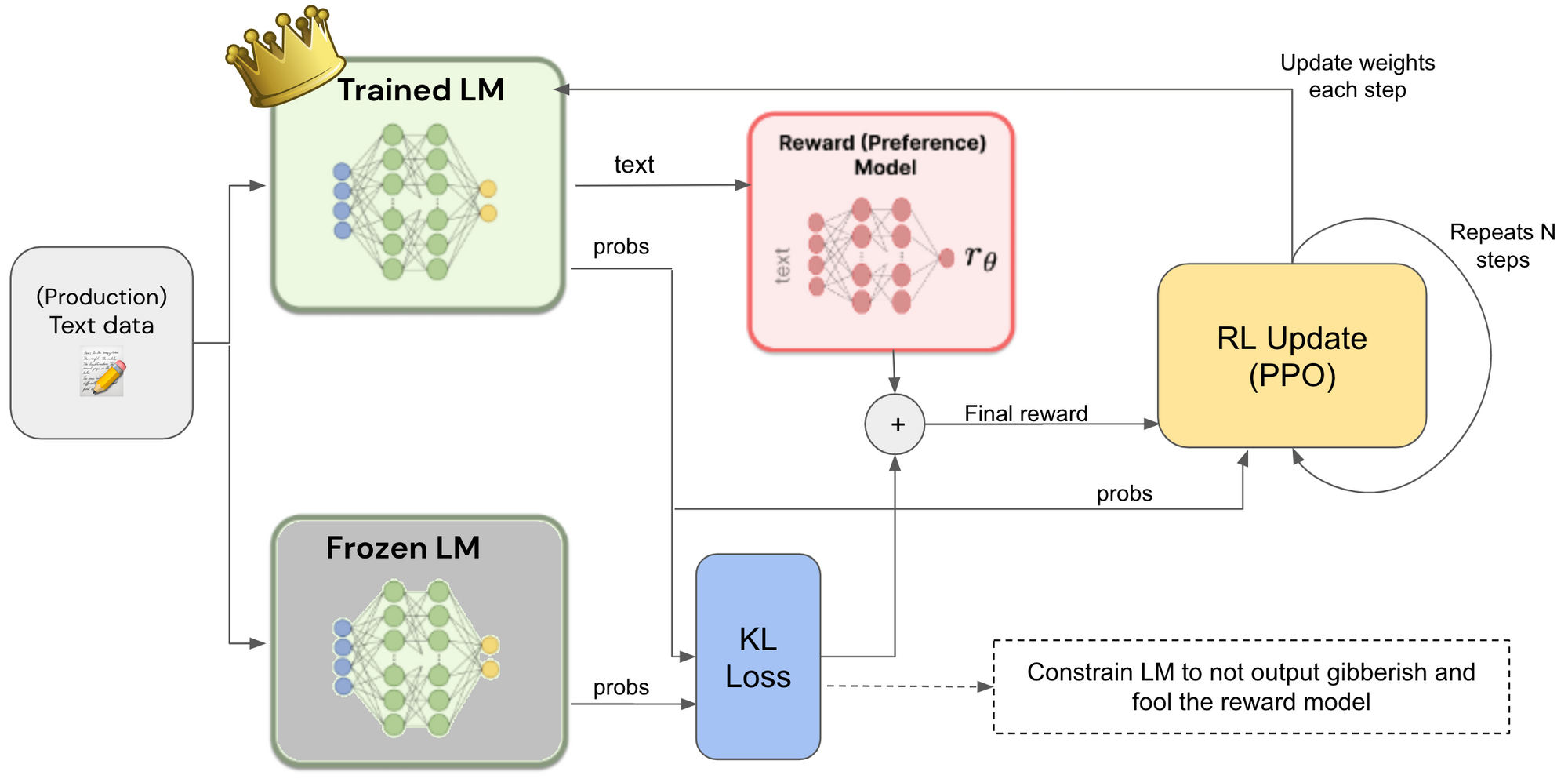
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
Maxproof
MaxProof is a framework designed for population-level test-time scaling in mathematical proof, specifically within the MiniMax-M3 series. It trains three key capabilities: proof generation, proof verification, and critique-conditioned proof repair.
arxiv.org
2 min
6/12/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026
RLHF from Scratch
The GitHub repository "ashworks1706/rlhf-from-scratch" provides a hands-on tutorial on Reinforcement Learning with Human Feedback (RLHF) and its applications in Large Language Models. It includes a simple Proximal Policy Optimization (PPO) training loop, helper routines for processing and reward computation, and a Jupyter notebook for experimentation.
github.com
1 min
2/11/2026
DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
DeepSeek-V4 is now supported for both inference and reinforcement learning (RL) training from Day 0. SGLang and Miles provide the first open-source stack designed for DeepSeek-V4’s hybrid sparse-attention architecture and manifold-constrained hyper-connections, utilizing FP4 expert weights.
lmsys.org
17 min
4/25/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
MiniMax M2.5 released: 80.2% in SWE-bench Verified
MiniMax M2.5 is a state-of-the-art AI model designed for real-world productivity, achieving scores of 80.2% in SWE-Bench Verified, 51.3% in Multi-SWE-Bench, and 76.3% in BrowseComp. It has been extensively trained using reinforcement learning across hundreds of thousands of complex environments, excelling in coding, agentic tool use, search, and office tasks.
minimax.io
13 min
2/12/2026
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
Maxproof
MaxProof is a framework designed for population-level test-time scaling in mathematical proof, specifically within the MiniMax-M3 series. It trains three key capabilities: proof generation, proof verification, and critique-conditioned proof repair.
arxiv.org
2 min
6/12/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
RLHF from Scratch
The GitHub repository "ashworks1706/rlhf-from-scratch" provides a hands-on tutorial on Reinforcement Learning with Human Feedback (RLHF) and its applications in Large Language Models. It includes a simple Proximal Policy Optimization (PPO) training loop, helper routines for processing and reward computation, and a Jupyter notebook for experimentation.
github.com
1 min
2/11/2026
DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
DeepSeek-V4 is now supported for both inference and reinforcement learning (RL) training from Day 0. SGLang and Miles provide the first open-source stack designed for DeepSeek-V4’s hybrid sparse-attention architecture and manifold-constrained hyper-connections, utilizing FP4 expert weights.
lmsys.org
17 min
4/25/2026
Chess engines do weird stuff
Chess engines like AlphaZero and lc0 use reinforcement learning by having the engine play itself multiple times to train the model on game outcomes. A combination of a weaker model and strong search capabilities can outperform a stronger model alone, as the search can significantly enhance performance.
girl.surgery
4 min
2/17/2026
Reinforcement Learning from Human Feedback
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
arxiv.org
2 min
2/7/2026
Hamilton-Jacobi-Bellman Equation: Reinforcement Learning and Diffusion Models
Richard Bellman's 1952 paper established the foundation for optimal control and reinforcement learning. His later work in the 1950s connected continuous-time systems to a previously published physical result from the 1840s, formulating the optimal condition as a partial differential equation (PDE).
dani2442.github.io
16 min
3/30/2026
MiniMax M2.5 released: 80.2% in SWE-bench Verified
MiniMax M2.5 is a state-of-the-art AI model designed for real-world productivity, achieving scores of 80.2% in SWE-Bench Verified, 51.3% in Multi-SWE-Bench, and 76.3% in BrowseComp. It has been extensively trained using reinforcement learning across hundreds of thousands of complex environments, excelling in coding, agentic tool use, search, and office tasks.
minimax.io
13 min
2/12/2026
No more articles to load