
Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
4d ago

Local LLM App by Ente
Ensu is Ente's offline LLM app designed to provide local language model capabilities, emphasizing privacy and control for users. The app aims to bridge the gap between advanced models and those that can run on personal devices, with its first release now available for download.
ente.com
5 min
4d ago
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
5d ago
Autoresearch on an old research idea
Karpathy's Autoresearch utilizes a constrained optimization loop with a large language model (LLM) agent. The author applied Autoresearch to legacy code from eCLIP while managing household tasks.
ykumar.me
6 min
6d ago

Project Nomad – Knowledge That Never Goes Offline
Project NOMAD is a free, open-source offline server that allows users to download and access Wikipedia, educational guides, and medical references without an internet connection. It enables the installation of local AI and large language models (LLMs) on any computer, providing a cost-effective alternative to similar products that typically charge hundreds of dollars.
projectnomad.us
3 min
3/22/2026
Flash-MoE: Running a 397B Parameter Model on a Laptop
Flash-Moe is a pure C/Metal inference engine that runs the Qwen3.5-397B-A17B model, a 397 billion parameter Mixture-of-Experts model, on a MacBook Pro with 48GB RAM at over 4.4 tokens per second. The 209GB model streams from SSD using a custom Metal compute pipeline without relying on Python or other frameworks.
github.com
6 min
3/22/2026

We rewrote our Rust WASM Parser in TypeScript – and it got 3x Faster
OpenUI is rewriting its openui-lang parser from Rust to TypeScript to improve latency in converting a custom DSL emitted by an LLM into a React component tree. The original Rust-based parser utilized a six-stage pipeline but was found to be optimizing the wrong aspects for performance.
openui.com
7 min
3/20/2026
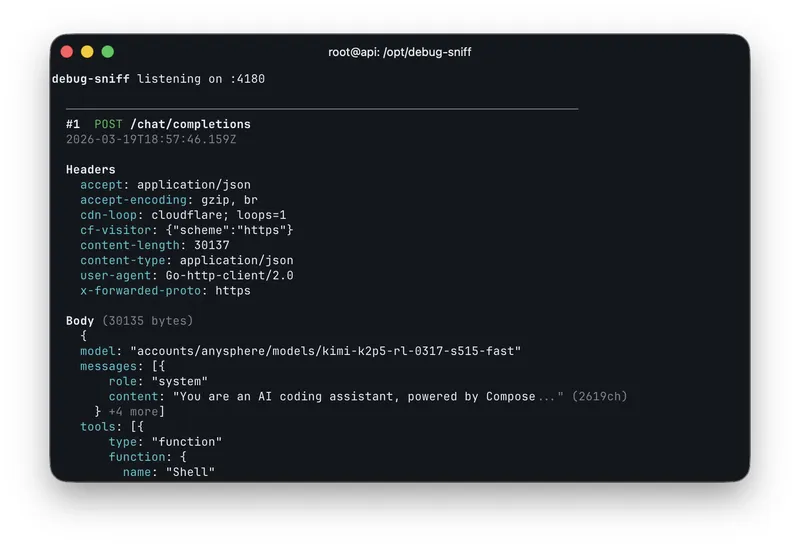
Cursor Composer 2 is just Kimi K2.5 with RL
Fynn discovered a model ID, "kimi-k2p5-rl-0317-s515-fast," while experimenting with the OpenAI base URL in Cursor. Composer 2 is identified as Kimi K2.5 with reinforcement learning (RL) capabilities.
twitter.com
1 min
3/20/2026
Anthropic takes legal action against OpenCode
Anthropic-specific references have been removed from the codebase to comply with legal requirements, including the branded system prompt file. The changes include the addition of headers for requests when the providerID starts with 'opencode'.
github.com
3 min
3/20/2026
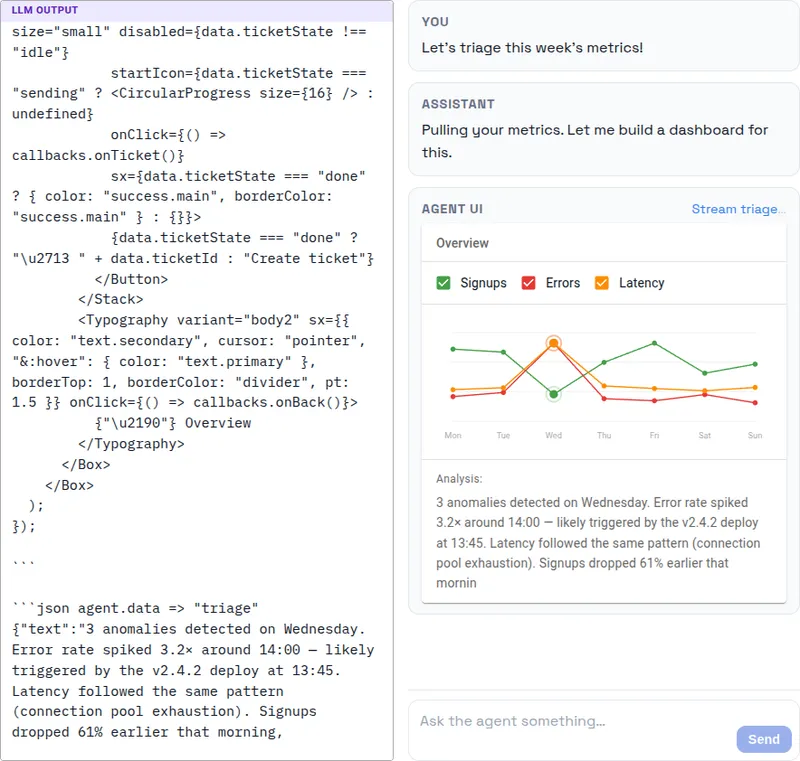
I turned Markdown into a protocol for generative UI
User interfaces are predicted to become obsolete, with agents generating necessary UIs on demand. A prototype demonstrates an agentic AI assistant that creates React UIs using Markdown as a protocol for text, executable code, and data streaming.
fabian-kuebler.com
7 min
3/19/2026
Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
4d ago
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
5d ago
Project Nomad – Knowledge That Never Goes Offline
Project NOMAD is a free, open-source offline server that allows users to download and access Wikipedia, educational guides, and medical references without an internet connection. It enables the installation of local AI and large language models (LLMs) on any computer, providing a cost-effective alternative to similar products that typically charge hundreds of dollars.
projectnomad.us
3 min
3/22/2026
We rewrote our Rust WASM Parser in TypeScript – and it got 3x Faster
OpenUI is rewriting its openui-lang parser from Rust to TypeScript to improve latency in converting a custom DSL emitted by an LLM into a React component tree. The original Rust-based parser utilized a six-stage pipeline but was found to be optimizing the wrong aspects for performance.
openui.com
7 min
3/20/2026
Anthropic takes legal action against OpenCode
Anthropic-specific references have been removed from the codebase to comply with legal requirements, including the branded system prompt file. The changes include the addition of headers for requests when the providerID starts with 'opencode'.
github.com
3 min
3/20/2026
Local LLM App by Ente
Ensu is Ente's offline LLM app designed to provide local language model capabilities, emphasizing privacy and control for users. The app aims to bridge the gap between advanced models and those that can run on personal devices, with its first release now available for download.
ente.com
5 min
4d ago
Autoresearch on an old research idea
Karpathy's Autoresearch utilizes a constrained optimization loop with a large language model (LLM) agent. The author applied Autoresearch to legacy code from eCLIP while managing household tasks.
ykumar.me
6 min
6d ago
Flash-MoE: Running a 397B Parameter Model on a Laptop
Flash-Moe is a pure C/Metal inference engine that runs the Qwen3.5-397B-A17B model, a 397 billion parameter Mixture-of-Experts model, on a MacBook Pro with 48GB RAM at over 4.4 tokens per second. The 209GB model streams from SSD using a custom Metal compute pipeline without relying on Python or other frameworks.
github.com
6 min
3/22/2026
Cursor Composer 2 is just Kimi K2.5 with RL
Fynn discovered a model ID, "kimi-k2p5-rl-0317-s515-fast," while experimenting with the OpenAI base URL in Cursor. Composer 2 is identified as Kimi K2.5 with reinforcement learning (RL) capabilities.
twitter.com
1 min
3/20/2026
I turned Markdown into a protocol for generative UI
User interfaces are predicted to become obsolete, with agents generating necessary UIs on demand. A prototype demonstrates an agentic AI assistant that creates React UIs using Markdown as a protocol for text, executable code, and data streaming.
fabian-kuebler.com
7 min
3/19/2026
Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
4d ago
Autoresearch on an old research idea
Karpathy's Autoresearch utilizes a constrained optimization loop with a large language model (LLM) agent. The author applied Autoresearch to legacy code from eCLIP while managing household tasks.
ykumar.me
6 min
6d ago
We rewrote our Rust WASM Parser in TypeScript – and it got 3x Faster
OpenUI is rewriting its openui-lang parser from Rust to TypeScript to improve latency in converting a custom DSL emitted by an LLM into a React component tree. The original Rust-based parser utilized a six-stage pipeline but was found to be optimizing the wrong aspects for performance.
openui.com
7 min
3/20/2026
I turned Markdown into a protocol for generative UI
User interfaces are predicted to become obsolete, with agents generating necessary UIs on demand. A prototype demonstrates an agentic AI assistant that creates React UIs using Markdown as a protocol for text, executable code, and data streaming.
fabian-kuebler.com
7 min
3/19/2026
Local LLM App by Ente
Ensu is Ente's offline LLM app designed to provide local language model capabilities, emphasizing privacy and control for users. The app aims to bridge the gap between advanced models and those that can run on personal devices, with its first release now available for download.
ente.com
5 min
4d ago
Project Nomad – Knowledge That Never Goes Offline
Project NOMAD is a free, open-source offline server that allows users to download and access Wikipedia, educational guides, and medical references without an internet connection. It enables the installation of local AI and large language models (LLMs) on any computer, providing a cost-effective alternative to similar products that typically charge hundreds of dollars.
projectnomad.us
3 min
3/22/2026
Cursor Composer 2 is just Kimi K2.5 with RL
Fynn discovered a model ID, "kimi-k2p5-rl-0317-s515-fast," while experimenting with the OpenAI base URL in Cursor. Composer 2 is identified as Kimi K2.5 with reinforcement learning (RL) capabilities.
twitter.com
1 min
3/20/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
5d ago
Flash-MoE: Running a 397B Parameter Model on a Laptop
Flash-Moe is a pure C/Metal inference engine that runs the Qwen3.5-397B-A17B model, a 397 billion parameter Mixture-of-Experts model, on a MacBook Pro with 48GB RAM at over 4.4 tokens per second. The 209GB model streams from SSD using a custom Metal compute pipeline without relying on Python or other frameworks.
github.com
6 min
3/22/2026
Anthropic takes legal action against OpenCode
Anthropic-specific references have been removed from the codebase to comply with legal requirements, including the branded system prompt file. The changes include the addition of headers for requests when the providerID starts with 'opencode'.
github.com
3 min
3/20/2026