Tree Search Distillation for Language Models Using PPO
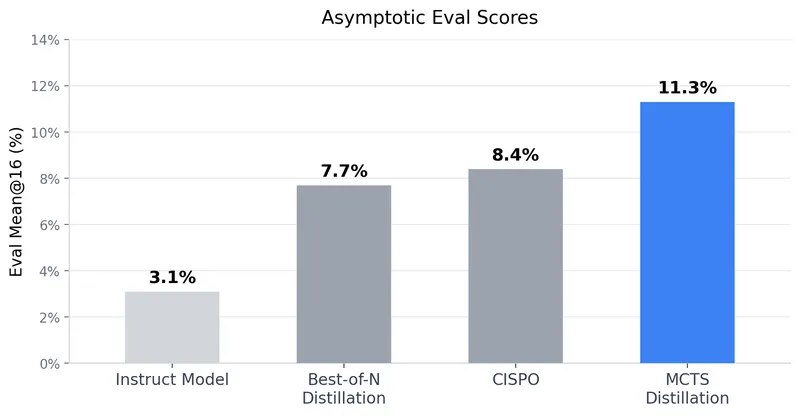
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
Tree Search Distillation for Language Models Using PPO
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
ayushtambde.com
10 min
3/15/2026
No more articles to load