Tree Search Distillation for Language Models Using PPO
ayushtambde.com
March 15, 2026
10 min read
🔥🔥🔥🔥🔥
49/100
Summary
Tree Search Distillation utilizes Proximal Policy Optimization (PPO) to enhance language models by integrating a test-time search mechanism similar to that used in game-playing neural networks like AlphaZero. The method aims to distill a stronger, augmented policy back into the language model, addressing the limitations observed in previous attempts with Monte Carlo Tree Search (MCTS).
Key Takeaways
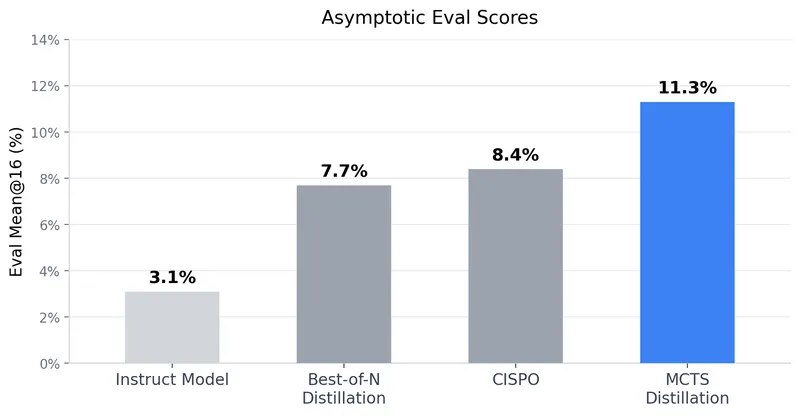
- The distilled model using Monte Carlo Tree Search (MCTS) achieved an asymptotic mean@16 eval score of 11.3% on the Countdown task, significantly improving from 3.1% of the pre-RL instruct model.
- The research indicates that combinatorial problems like Countdown may benefit more from parallel adaptive reasoning tree search compared to sequential reasoning tasks.
- A dense reward function was found to stabilize training, while evaluation utilized a sparse reward function to assess performance intuitively.
- The study suggests that traditional MCTS may not be as effective in language modeling due to the nature of token actions, which often include fillers or syntactic elements.