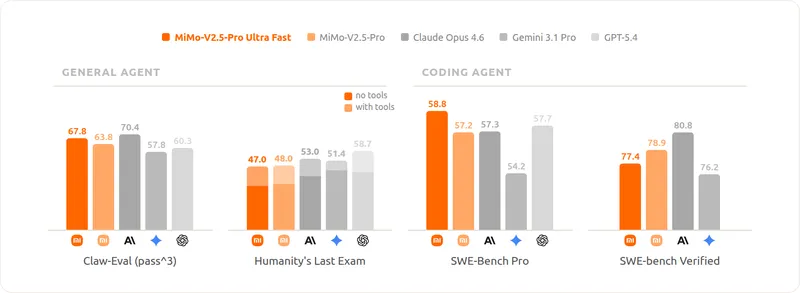
MiMo-v2.5-Pro-UltraSpeed: 1T model with 1000 tokens per second
Xiaomi has released the MiMo-V2.5-Pro-UltraSpeed, capable of generating 1 trillion parameter models at a speed of 1000 transactions per second (TPS). This advancement enhances real-time AI reasoning and collaboration, making it more responsive and integrated into human thought processes.
mimo.xiaomi.com
8 min
4d ago

A sleep-like consolidation mechanism for LLMs
Transformer-based large language models struggle with long-context tasks due to poor scaling of their attention mechanism. Implementing a sleep-like consolidation mechanism allows models to convert recent context into persistent fast weights while clearing their key-value cache.
arxiv.org
2 min
5/26/2026

Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
3/25/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026
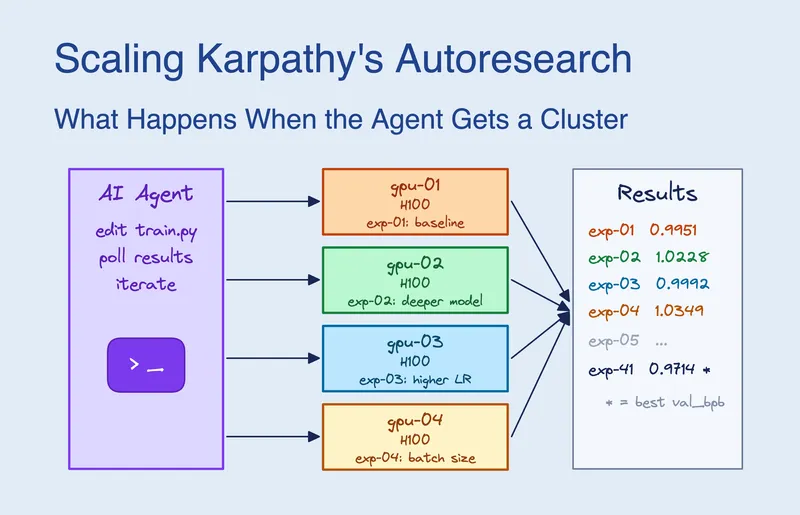
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
MiMo-v2.5-Pro-UltraSpeed: 1T model with 1000 tokens per second
Xiaomi has released the MiMo-V2.5-Pro-UltraSpeed, capable of generating 1 trillion parameter models at a speed of 1000 transactions per second (TPS). This advancement enhances real-time AI reasoning and collaboration, making it more responsive and integrated into human thought processes.
mimo.xiaomi.com
8 min
4d ago
Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
3/25/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
A sleep-like consolidation mechanism for LLMs
Transformer-based large language models struggle with long-context tasks due to poor scaling of their attention mechanism. Implementing a sleep-like consolidation mechanism allows models to convert recent context into persistent fast weights while clearing their key-value cache.
arxiv.org
2 min
5/26/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026
MiMo-v2.5-Pro-UltraSpeed: 1T model with 1000 tokens per second
Xiaomi has released the MiMo-V2.5-Pro-UltraSpeed, capable of generating 1 trillion parameter models at a speed of 1000 transactions per second (TPS). This advancement enhances real-time AI reasoning and collaboration, making it more responsive and integrated into human thought processes.
mimo.xiaomi.com
8 min
4d ago
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026
A sleep-like consolidation mechanism for LLMs
Transformer-based large language models struggle with long-context tasks due to poor scaling of their attention mechanism. Implementing a sleep-like consolidation mechanism allows models to convert recent context into persistent fast weights while clearing their key-value cache.
arxiv.org
2 min
5/26/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
Quantization from the Ground Up
Qwen-3-Coder-Next is an 80 billion parameter model that requires 159.4GB of RAM to run. Techniques exist to reduce the size of large language models by 4x and increase their speed by 2x.
ngrok.com
26 min
3/25/2026
No more articles to load