MiMo-v2.5-Pro-UltraSpeed: 1T model with 1000 tokens per second
mimo.xiaomi.com
June 8, 2026
8 min read
🔥🔥🔥🔥🔥
70/100
Summary
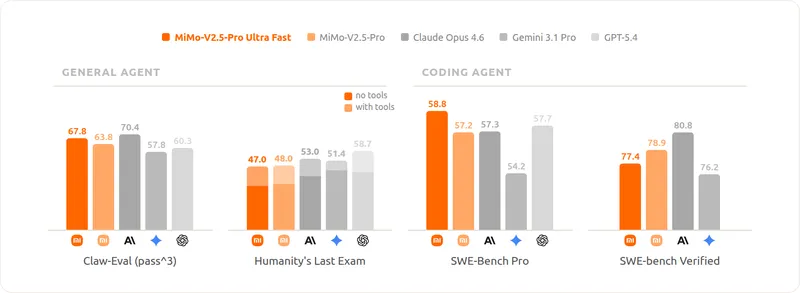
Xiaomi has released the MiMo-V2.5-Pro-UltraSpeed, capable of generating 1 trillion parameter models at a speed of 1000 transactions per second (TPS). This advancement enhances real-time AI reasoning and collaboration, making it more responsive and integrated into human thought processes.
Key Takeaways
- Xiaomi released the MiMo-V2.5-Pro-UltraSpeed, achieving over 1000 tokens per second (tps) decode speed on a 1-trillion-parameter model for the first time.
- The new model allows for parallel reasoning paths, enhancing the quality of AI-generated responses and enabling real-time decision-making in critical applications.
- The MiMo-V2.5-Pro-UltraSpeed API is available through a limited-time application process, prioritizing enterprises and professional developers, with trial access from June 9 to June 23, 2026.
- The model's speed significantly improves coding efficiency, allowing developers to generate code without the delays previously caused by inference latency.
Community Sentiment
Positives
- The introduction of MiMo-v2.5-Pro-UltraSpeed, achieving 1000 tokens per second, signifies a major leap in model efficiency, potentially transforming real-time AI applications.
- The prospect of compute-in-memory technology could lead to models that are not only faster but also significantly smarter, enhancing the capabilities of AI systems.
- Ultrafast AI could streamline workflows, allowing developers to focus more deeply on complex problems rather than getting bogged down in lengthy processes.
- The ability to render UIs directly from context data and prompts could revolutionize software development, making it more accessible for small businesses.
Concerns
- There are concerns that the rapid pace of AI development may lead to a proliferation of low-quality software, overshadowing genuine advancements.
- The shift towards ultrafast AI might diminish the enjoyment of the craft for developers, as the focus shifts from deep problem-solving to quick fixes.
- The increasing costs associated with AI usage, particularly from American providers, could create barriers for many companies, complicating the landscape for developers.
- The inconsistency in model performance and pricing from AI providers raises concerns about reliability and predictability in AI applications.
Related Articles
Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
May 29, 2026

Xiaomi MiMo-v2.5 Series API Permanent Price Reduction Up to 99%
May 26, 2026
Flash-MoE: Running a 397B Parameter Model on a Laptop
Mar 22, 2026

Accelerating Gemma 4: faster inference with multi-token prediction drafters
May 5, 2026

A 10 year old Xeon is all you need
Jun 1, 2026