
Gemma 4 QAT models: Optimizing compression for mobile and laptop efficiency
Gemma 4 has introduced Multi-Token Prediction (MTP) to enhance inference speed. New checkpoints optimized with Quantization-Aware Training (QAT) have been released to improve efficiency for mobile and laptop use.
blog.google
4 min
6/5/2026

Accelerating Gemma 4: faster inference with multi-token prediction drafters
Gemma 4 now features Multi-Token Prediction (MTP) drafters, enhancing inference speed and efficiency. This update aims to improve performance across developer workstations, mobile devices, and cloud environments.
blog.google
4 min
5/5/2026

Google Gemma 4 Runs Natively on iPhone with Full Offline AI Inference
Google's Gemma 4 model family now runs natively on iPhones, enabling full local AI inference offline. Early benchmarks show the 31B variant of Gemma 4 performing comparably to Qwen 3.5's 27B model.
gizmoweek.com
2 min
4/15/2026
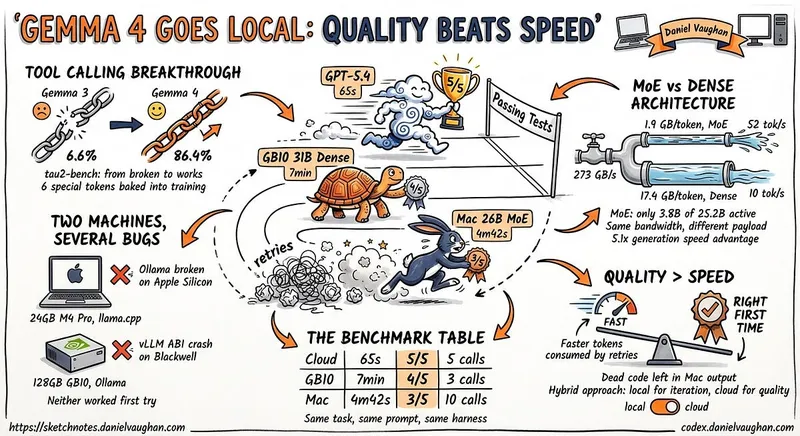
I ran Gemma 4 as a local model in Codex CLI
Gemma 4 was tested as a local model in Codex CLI to determine its viability as a replacement for cloud models in coding tasks. The testing involved using a 24 GB M4 Pro MacBook Pro to evaluate Gemma 4's local tool calling capabilities.
blog.danielvaughan.com
7 min
4/12/2026

April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026

Google releases Gemma 4 open models
Gemma 4 delivers maximum compute and memory efficiency for mobile and IoT devices, enhancing intelligence in these platforms. It supports the development of autonomous agents capable of planning, navigating apps, and completing tasks, while also offering strong audio and visual understanding for rich multimodal applications and multilingual experiences that extend beyond simple translation.
deepmind.google
1 min
4/2/2026
Gemma 4 QAT models: Optimizing compression for mobile and laptop efficiency
Gemma 4 has introduced Multi-Token Prediction (MTP) to enhance inference speed. New checkpoints optimized with Quantization-Aware Training (QAT) have been released to improve efficiency for mobile and laptop use.
blog.google
4 min
6/5/2026
Google Gemma 4 Runs Natively on iPhone with Full Offline AI Inference
Google's Gemma 4 model family now runs natively on iPhones, enabling full local AI inference offline. Early benchmarks show the 31B variant of Gemma 4 performing comparably to Qwen 3.5's 27B model.
gizmoweek.com
2 min
4/15/2026
April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026
Accelerating Gemma 4: faster inference with multi-token prediction drafters
Gemma 4 now features Multi-Token Prediction (MTP) drafters, enhancing inference speed and efficiency. This update aims to improve performance across developer workstations, mobile devices, and cloud environments.
blog.google
4 min
5/5/2026
I ran Gemma 4 as a local model in Codex CLI
Gemma 4 was tested as a local model in Codex CLI to determine its viability as a replacement for cloud models in coding tasks. The testing involved using a 24 GB M4 Pro MacBook Pro to evaluate Gemma 4's local tool calling capabilities.
blog.danielvaughan.com
7 min
4/12/2026
Google releases Gemma 4 open models
Gemma 4 delivers maximum compute and memory efficiency for mobile and IoT devices, enhancing intelligence in these platforms. It supports the development of autonomous agents capable of planning, navigating apps, and completing tasks, while also offering strong audio and visual understanding for rich multimodal applications and multilingual experiences that extend beyond simple translation.
deepmind.google
1 min
4/2/2026
Gemma 4 QAT models: Optimizing compression for mobile and laptop efficiency
Gemma 4 has introduced Multi-Token Prediction (MTP) to enhance inference speed. New checkpoints optimized with Quantization-Aware Training (QAT) have been released to improve efficiency for mobile and laptop use.
blog.google
4 min
6/5/2026
I ran Gemma 4 as a local model in Codex CLI
Gemma 4 was tested as a local model in Codex CLI to determine its viability as a replacement for cloud models in coding tasks. The testing involved using a 24 GB M4 Pro MacBook Pro to evaluate Gemma 4's local tool calling capabilities.
blog.danielvaughan.com
7 min
4/12/2026
Accelerating Gemma 4: faster inference with multi-token prediction drafters
Gemma 4 now features Multi-Token Prediction (MTP) drafters, enhancing inference speed and efficiency. This update aims to improve performance across developer workstations, mobile devices, and cloud environments.
blog.google
4 min
5/5/2026
April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026
Google Gemma 4 Runs Natively on iPhone with Full Offline AI Inference
Google's Gemma 4 model family now runs natively on iPhones, enabling full local AI inference offline. Early benchmarks show the 31B variant of Gemma 4 performing comparably to Qwen 3.5's 27B model.
gizmoweek.com
2 min
4/15/2026
Google releases Gemma 4 open models
Gemma 4 delivers maximum compute and memory efficiency for mobile and IoT devices, enhancing intelligence in these platforms. It supports the development of autonomous agents capable of planning, navigating apps, and completing tasks, while also offering strong audio and visual understanding for rich multimodal applications and multilingual experiences that extend beyond simple translation.
deepmind.google
1 min
4/2/2026
No more articles to load