I ran Gemma 4 as a local model in Codex CLI
blog.danielvaughan.com
April 12, 2026
7 min read
🔥🔥🔥🔥🔥
61/100
Summary
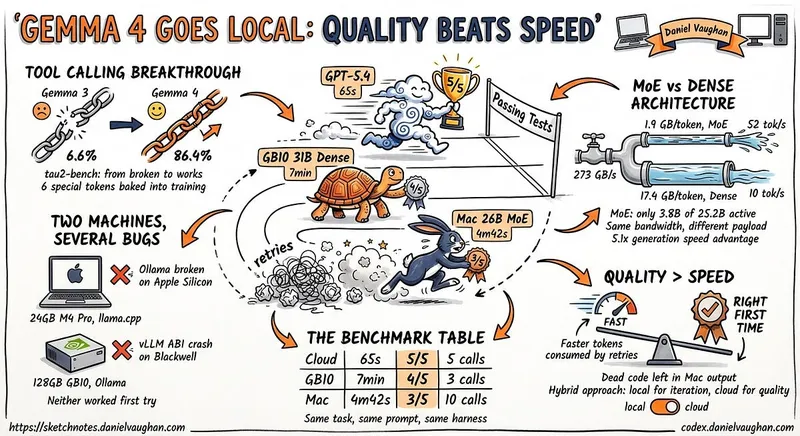
Gemma 4 was tested as a local model in Codex CLI to determine its viability as a replacement for cloud models in coding tasks. The testing involved using a 24 GB M4 Pro MacBook Pro to evaluate Gemma 4's local tool calling capabilities.
Key Takeaways
- Gemma 4 achieved an 86.4% success rate on the tau2-bench function-calling benchmark, significantly improving its tool-calling capabilities compared to previous versions.
- The author ran Gemma 4 locally on two different machines, a MacBook Pro and a Dell Pro Max, to evaluate its performance against cloud models.
- Local models like Gemma 4 offer advantages in cost, privacy, and resilience compared to cloud-based APIs.
- Setting up Gemma 4 required troubleshooting various bugs and configuration adjustments, particularly with the Codex CLI and model compatibility.
Community Sentiment
Positives
- Running Gemma 4 on local hardware like the M3 Ultra demonstrates the model's capability to handle large context sizes effectively, which is crucial for complex tasks.
- The integration of Gemma 4 with tools like Zed via ACP showcases its versatility and ease of use in real-world applications.
- Users report significant performance improvements with the M5 Pro, indicating that hardware upgrades can lead to enhanced model efficiency and speed.
- The ability to offload MoE tasks to the CPU allows for flexibility in managing context size and token generation speed, which can optimize performance.
Concerns
- Concerns about the quality of fine-tuned models compared to original versions suggest skepticism about performance claims, highlighting the need for thorough benchmarking.
- Issues with tool calling in models like Qwen 3.5 indicate that practical challenges remain, which can hinder user experience and effectiveness in coding tasks.
- The necessity of increasing context size to achieve useful results points to potential limitations in the model's default configurations, which may not meet all user needs.
Related Articles
Running Gemma 4 locally with LM Studio's new headless CLI and Claude Code
Apr 5, 2026

How to setup a local coding agent on macOS
Jun 12, 2026
Running Gemma 4 26B at 5 tokens/sec on a 13-year-old Xeon with no GPU
Jul 15, 2026

Local Qwen isn't a worse Opus, it's a different tool
Jun 18, 2026

Qwen 3.6 27B is the sweet spot for local development
Jun 29, 2026