Accelerating Gemma 4: faster inference with multi-token prediction drafters

blog.google
May 5, 2026
4 min read
🔥🔥🔥🔥🔥
71/100
Summary
Gemma 4 now features Multi-Token Prediction (MTP) drafters, enhancing inference speed and efficiency. This update aims to improve performance across developer workstations, mobile devices, and cloud environments.
Key Takeaways
- Google introduced Multi-Token Prediction (MTP) drafters for Gemma 4, achieving up to a 3x speedup in inference without compromising output quality.
- Speculative decoding allows the MTP drafter to predict multiple tokens simultaneously, significantly reducing latency during token generation.
- Developers can enhance responsiveness and performance for applications by pairing Gemma 4 models with MTP drafters, enabling faster outputs on consumer-grade hardware.
- The implementation of MTP drafters maintains identical reasoning and accuracy as the primary Gemma 4 model while delivering results more quickly.
Community Sentiment
Positives
- The introduction of multi-token prediction (MTP) significantly enhances inference speed without compromising quality, which could lead to more efficient AI applications.
- Recent performance improvements in local models demonstrate the rapid advancements in AI capabilities, suggesting a bright future for self-hosted solutions.
- The small memory overhead associated with drafter models indicates a promising direction for lightweight AI applications, making advanced models more accessible.
Concerns
- Concerns about Google's lack of promotion for its cloud services for Gemma 4 suggest potential missed opportunities for monetization and user engagement.
- The complexity of implementing MTP in existing frameworks like LM Studio raises questions about accessibility and user experience for developers.
Related Articles

Gemma 4 12B: A unified, encoder-free multimodal model
Jun 3, 2026

Gemma 4 QAT models: Optimizing compression for mobile and laptop efficiency
Jun 5, 2026

DiffusionGemma: 4x Faster Text Generation
Jun 10, 2026

How to setup a local coding agent on macOS
Jun 12, 2026
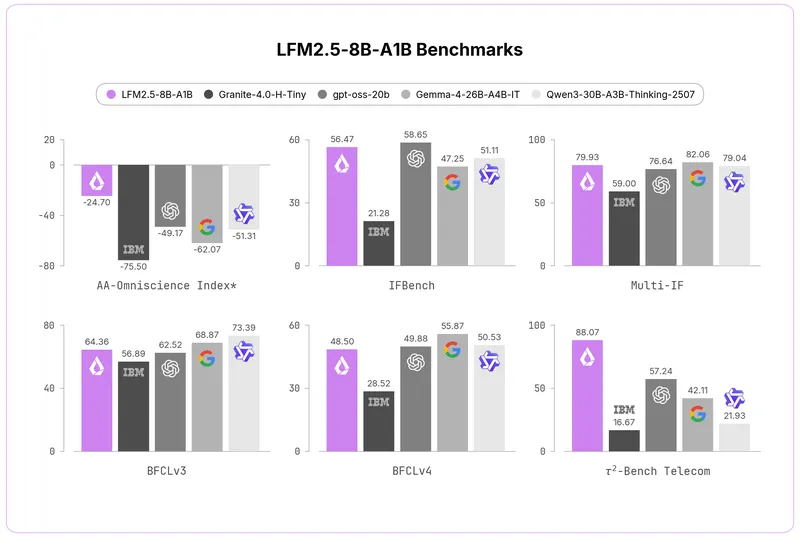
Liquid AI reveals 8B-A1B MoE trained on 38T
May 29, 2026