Evaluating and mitigating the growing risk of LLM-discovered 0-days

red.anthropic.com
February 5, 2026
10 min read
🔥🔥🔥🔥🔥
44/100
Summary
Claude Opus 4.6 features significant advancements in AI models' cybersecurity capabilities. Experts believe the current moment is critical for accelerating the defensive use of AI in response to the increasing risk of LLM-discovered zero-day vulnerabilities.
Key Takeaways
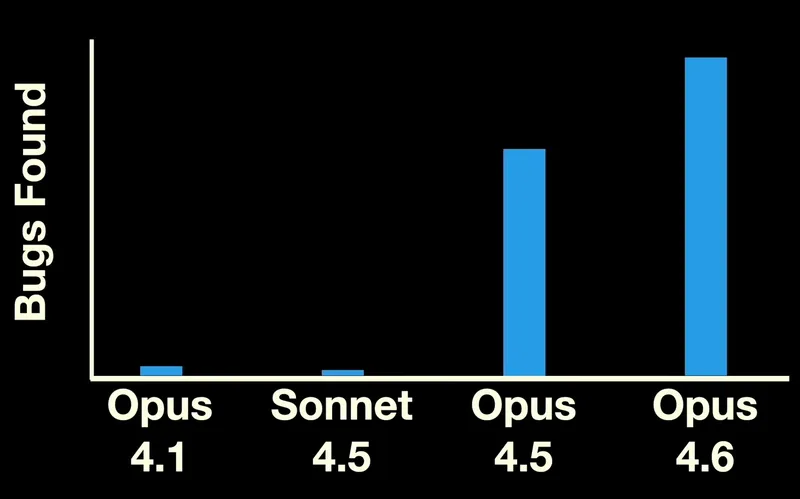
- Claude Opus 4.6 can identify high-severity vulnerabilities in code at scale, outperforming previous models without the need for specialized tools or prompts.
- The team has discovered and validated over 500 high-severity vulnerabilities in open source software, contributing human-reviewed patches to address these issues.
- Opus 4.6 analyzes code by reasoning similarly to human researchers, identifying patterns and past fixes to uncover vulnerabilities that have remained undetected for decades.
- The initiative aims to enhance cybersecurity by empowering defenders and securing open source projects that are critical to internet infrastructure.
Community Sentiment
Positives
- Opus 4.6 represents a significant advancement in security research capabilities, demonstrating its potential to discover vulnerabilities that would have been difficult to find with earlier models.
- The involvement of human validation in patching vulnerabilities is a crucial step towards enhancing the reliability and safety of AI systems.
Concerns
- The article lacks technical depth and reads more like a marketing piece than a substantive evaluation of AI capabilities.
- Critics argue that the methods discussed, such as grepping for specific functions, do not reflect the sophistication expected from leading AI research.