GLM 5.2 beats Claude in our benchmarks

semgrep.dev
June 28, 2026
9 min read
🔥🔥🔥🔥🔥
63/100
Summary
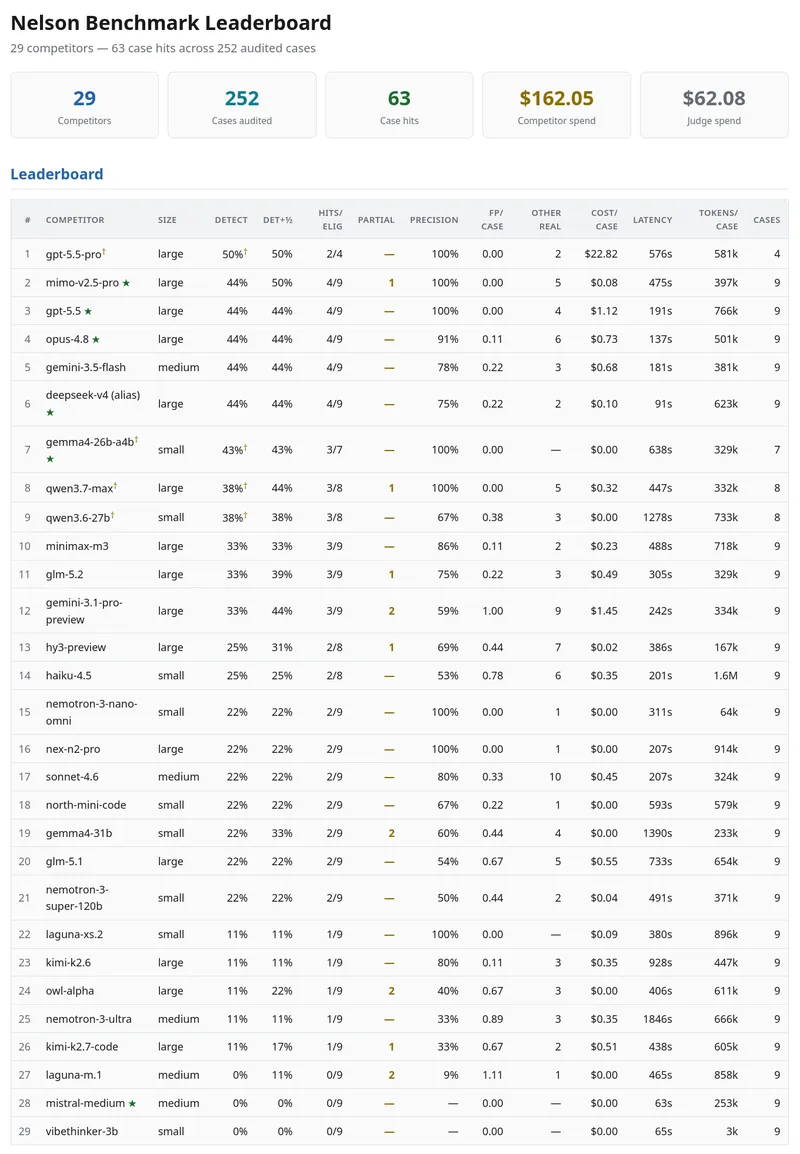
GLM 5.2 from Zhipu AI achieved a 39% F1 score on the IDOR detection benchmark, outperforming Claude Code, which scored 32%. Both models were evaluated on the same dataset and prompt, with GLM 5.2 costing approximately $0.17 per vulnerability found.
Key Takeaways
- GLM 5.2 from Zhipu AI scored 39% F1 on IDOR detection, outperforming Claude Code's 32% at a cost of approximately $0.17 per vulnerability found.
- GLM 5.2 is an open-weight model, allowing users to download, run, and fine-tune it in their own environments under an MIT license.
- The model features a Mixture-of-Experts architecture with 750 billion total parameters and extends usable context from 200K to 1M tokens, enhancing its performance on complex security tasks.
- Semgrep's multimodal pipeline achieved 53–61% F1 on IDOR detection, indicating that the performance of models can significantly depend on the harness used.
Community Sentiment
Positives
- GLM 5.2 is proving to be a reliable workhorse model for daily programming tasks, offering significant cost savings compared to other APIs.
- The model excels at finding and fixing vulnerabilities, demonstrating its strong performance in practical applications.
- With 753 billion parameters, GLM 5.2 showcases impressive capabilities that could rival larger models while remaining accessible.
Concerns
- Concerns about potential export controls on open models could hinder access to powerful AI tools, impacting innovation and security.
- The comparison to Claude and other models raises questions about the practicality and cost-effectiveness of running such large models locally.
- Skepticism exists regarding the legal feasibility of imposing export restrictions on AI models, indicating a complex regulatory landscape.