I put a datacenter GPU in my gaming PC

blog.tymscar.com
May 31, 2026
14 min read
🔥🔥🔥🔥🔥
63/100
Summary
A datacenter GPU was installed in a gaming PC using an adapter, providing a total of 32GB of VRAM across two GPUs. This setup allows for running a 27 billion parameter model at 32 tokens.
Key Takeaways
- A Tesla V100 SXM2 GPU with 16GB of HBM2 memory was purchased for about £150 and adapted for use in a gaming PC, providing a total of 32GB of VRAM when combined with an RTX 4080.
- The V100 GPU offers 900 GB/s of memory bandwidth, surpassing the bandwidth of newer consumer GPUs, including the RTX 4080 and Apple’s M3 Max.
- An SXM2-to-PCIe adapter was used to connect the V100 GPU to the gaming PC, costing around £50, allowing for significant cost savings compared to purchasing a high-end consumer GPU.
- The V100's cooling fan operates at 82 decibels and cannot be controlled, making it unsuitable for quiet environments.
Community Sentiment
Positives
- Decommissioned datacenter GPUs like the NVIDIA V100 and AMD MI50 are becoming accessible for local experimentation, fostering a community of enthusiasts who keep these models relevant.
- The cottage industry of 3D-printed fan shrouds for datacenter GPUs enhances cooling efficiency, which is crucial for maintaining performance during intensive tasks.
- The AMD MI250X offers impressive specifications with 128GB of HBM2E memory, making it a compelling option for high-throughput AI applications, despite connection challenges.
Concerns
- The NVIDIA V100's lack of bfloat16 support highlights its aging hardware features, which could limit its effectiveness for modern AI workloads.
- Slow prefill times in AI models can severely hinder performance, particularly for applications requiring rapid response, which is a significant drawback for local deployments.
- The complexity of integrating advanced GPUs like the MI250X into standard systems may deter users, as proprietary requirements can complicate accessibility.
Related Articles
Jamesob's guide to running SOTA LLMs locally
Jul 3, 2026

Benchmarking 15 "E-Waste" GPUs with Modern Workloads
Jul 13, 2026
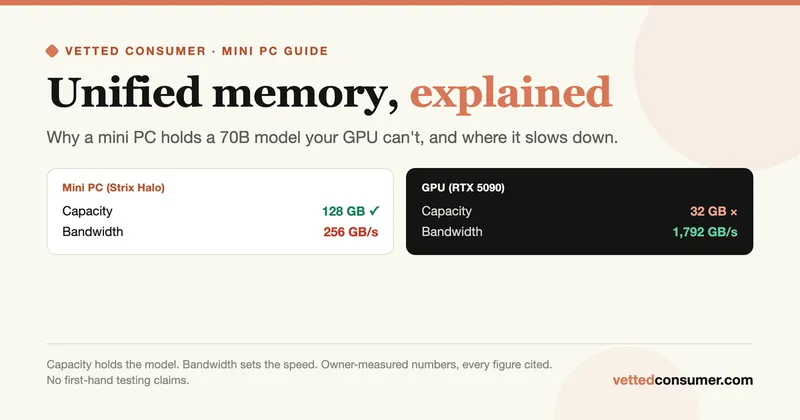
Unified Memory, Explained: Why Mini PCs Can Run 70B Models a Big GPU Can't
Jul 10, 2026

Local Qwen isn't a worse Opus, it's a different tool
Jun 18, 2026

RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
Jun 13, 2026