Liquid AI reveals 8B-A1B MoE trained on 38T
liquid.ai
May 29, 2026
6 min read
🔥🔥🔥🔥🔥
60/100
Summary
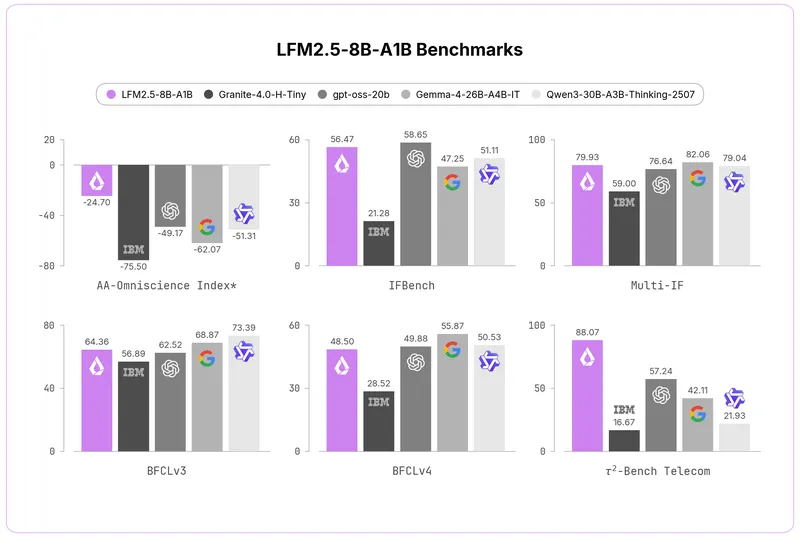
LFM2.5-8B-A1B is an edge model designed for efficient tool calling on consumer hardware, featuring a 128K context window and expanded pretraining from 12 trillion to 38 trillion tokens. The model's vocabulary has been doubled to enhance tokenization for non-Latin languages, enabling it to perform complex tasks on entry-level laptops.
Key Takeaways
- LFM2.5-8B-A1B features an expanded context window of 128,000 tokens and a doubled vocabulary size of 128,000 to enhance tokenization efficiency for non-Latin languages.
- The model is designed for on-device applications, capable of chaining tool calls and following complex instructions across various devices.
- LFM2.5-8B-A1B is a reasoning-only model that produces an explicit chain of thought before arriving at a final answer, improving performance without sacrificing speed.
- The model achieves competitive performance with larger models on instruction following and agentic tasks while being the fastest in its size class for CPU and GPU inference.
Community Sentiment
Positives
- Liquid AI's 8B-A1B model demonstrates impressive performance in summarizing long transcripts, showcasing its capabilities despite being a smaller model.
- The advancements in smaller models, like Qwen3.5:4B, highlight how effective fine-tuning and reinforcement learning can yield high performance on limited hardware.
- Liquid's focus on model training and fine-tuning allows for the creation of specialized tools that are fast, private, and do not require an internet connection.
Concerns
- The 8B-A1B model underperformed significantly in bug fixing benchmarks compared to older models, raising concerns about its competitive edge despite being a newer architecture.
- There are worries that Liquid AI may be overtraining their models with 38 trillion tokens, which could lead to diminishing returns in performance.



![[AINews] Why OpenAI Should Build Slack](https://substackcdn.com/image/fetch/$s_!XQAE!,w_1200,h_675,c_fill,f_jpg,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F89ee056a-0ea2-4473-8e1c-9b21f034c717_1474x2116.png)
