LLMs are not the black box you were promised
jay.ai
June 2, 2026
3 min read
🔥🔥🔥🔥🔥
44/100
Summary
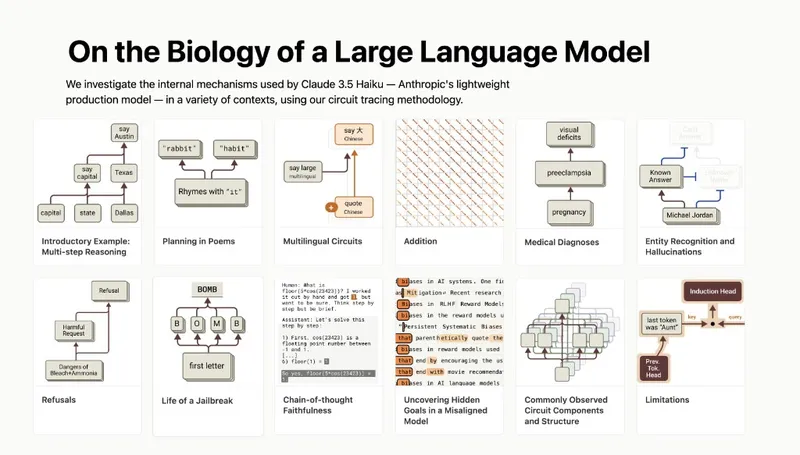
Mechanistic interpretability has advanced significantly, allowing deeper insights into the inner workings of large language models (LLMs). Anthropic's research, "On the Biology of a Large Language Model" (2025), represents a key milestone in understanding LLM behavior and thought processes.
Key Takeaways
- Mechanistic interpretability has advanced significantly, allowing researchers to reverse engineer the inner workings of large language models (LLMs).
- Anthropic's circuit tracing technique enables the identification of discrete concepts within LLMs by monitoring interactions during a forward pass, leading to human-interpretable features.
- LLMs demonstrate genuine multi-step reasoning by activating intermediary concepts, allowing for pseudo-symbolic inference similar to higher reasoning.
- Understanding a model's implicit reasoning can inform the design of better learning algorithms and improve model behavior.
Community Sentiment
Positives
- LLMs are increasingly recognized as integral to understanding intelligence, demonstrating capabilities that surpass many humans in specific intellectual tasks, which could reshape our view of AI.
- The ability of LLMs to perform tasks like web app development with ease highlights their potential to democratize technology, making it accessible to a broader audience.
- The ongoing research into understanding LLMs' internal workings could lead to better model behavior steering, enhancing safety and alignment in AI applications.
Concerns
- Concerns about the lack of metacognitive insight in LLMs suggest that these models may not truly understand their outputs, raising questions about their reliability in critical applications.
- Critics argue that LLMs often rely on superficial associations rather than genuine reasoning, which undermines claims of higher cognitive capabilities.
- There is skepticism regarding the accuracy of claims made about LLMs' interpretability and the origins of research, indicating a potential disconnect between public perception and academic understanding.