A real-world benchmark for AI code review
qodo.ai
February 4, 2026
8 min read
Summary
Qodo's code review benchmark 1.0 provides a rigorous methodology to objectively measure and validate the performance of AI-powered code review systems. The benchmark addresses limitations in existing methods that rely on backtracking from fix commits.
Key Takeaways
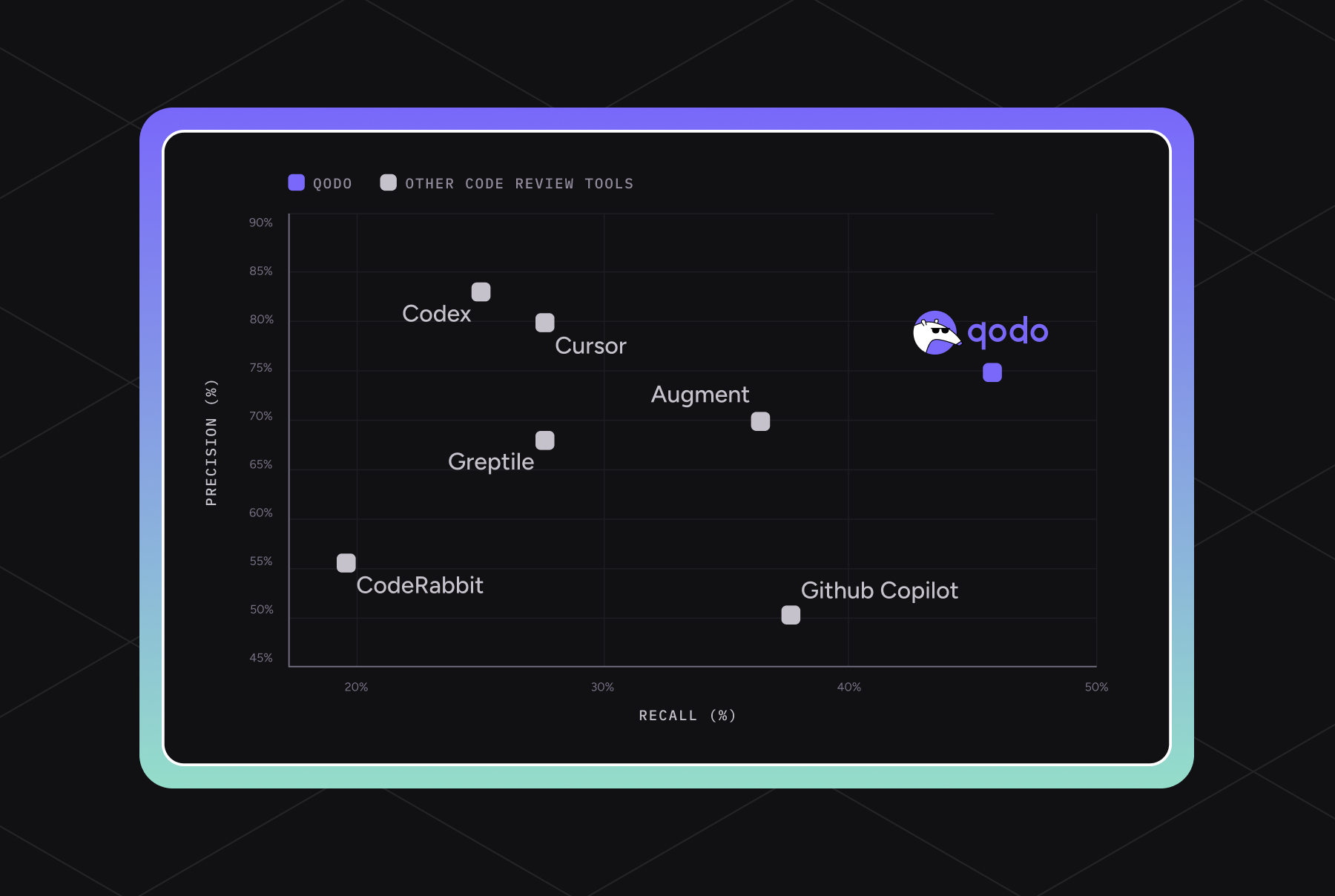
- Qodo developed a new code review benchmark (version 1.0) that measures AI code review systems' performance by injecting defects into real, merged pull requests from active open-source repositories.
- The benchmark evaluates both code correctness (bug detection) and code quality (best practice enforcement) across a larger scale of 100 pull requests containing 580 issues.
- In comparative evaluations, Qodo's model achieved an F1 score of 60.1%, outperforming seven other leading AI code review platforms.
- The benchmark methodology is scalable and repository-agnostic, allowing it to be applied to any codebase, whether open-source or private.
Community Sentiment
MixedPositives
- The introduction of a multi-agent expert review architecture in Qodo 2.0 could enhance the efficiency of code reviews by allowing specialized agents to handle distinct responsibilities.
Concerns
- The pricing model at $30/dev/mo with a limit of 20 PRs per month is impractical for teams with high PR volumes, potentially hindering adoption.
- There is no mention of measures to alleviate overfitting in the benchmark, raising concerns about the reliability of the results.
- The absence of anthropic models in their benchmark suggests that it may not adequately reflect the performance of state-of-the-art AI models.
Source
qodo.ai
Published
February 4, 2026
Reading Time
8 minutes
Relevance Score
43/100
🔥🔥🔥🔥🔥
Why It Matters
This page is optimized for focused reading: quick context up top, a clean summary block, and a direct path to the original source when you want the full story.