
How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026

ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
3/25/2026

Study: Self-generated Agent Skills are useless
SkillsBench is a benchmarking framework designed to evaluate the effectiveness of agent skills across 86 tasks in 11 domains. It includes curated skills and deterministic verifiers to assess their impact on large language model (LLM) agents during inference.
arxiv.org
2 min
2/16/2026

Frontier AI agents violate ethical constraints 30–50% of time, pressured by KPIs
A new benchmark evaluates outcome-driven constraint violations in autonomous AI agents to enhance safety and alignment with human values. This benchmark addresses limitations of existing safety assessments that mainly focus on harmful actions.
arxiv.org
2 min
2/10/2026
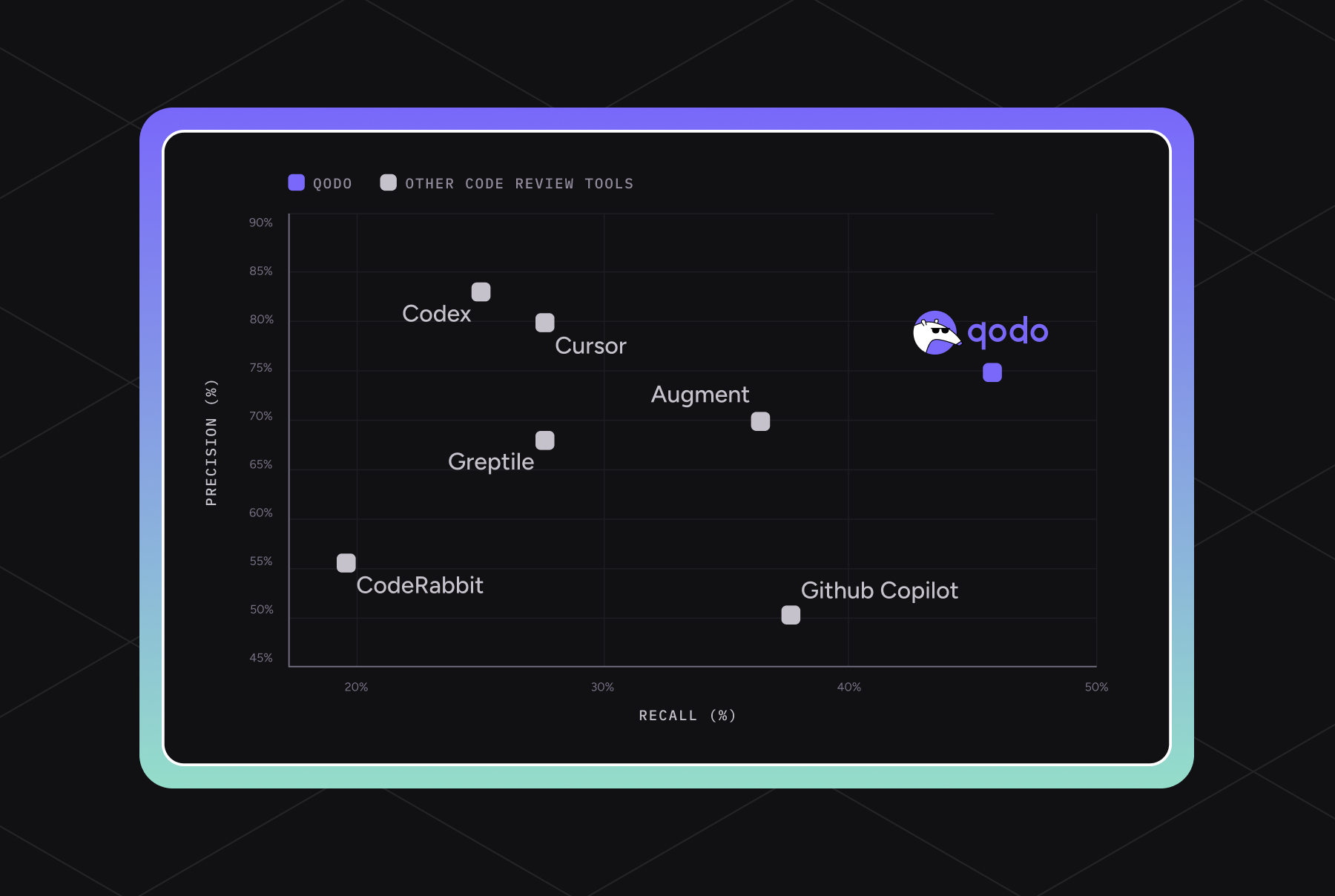
A real-world benchmark for AI code review
Qodo's code review benchmark 1.0 provides a rigorous methodology to objectively measure and validate the performance of AI-powered code review systems. The benchmark addresses limitations in existing methods that rely on backtracking from fix commits.
qodo.ai
8 min
2/4/2026

Advancing AI Benchmarking with Game Arena
Google DeepMind and Kaggle launched Game Arena, a public benchmarking platform for AI models to compete in strategic games, starting with chess. The platform aims to develop AI capable of making decisions in environments with incomplete information.
blog.google
5 min
2/2/2026

Which AI Lies Best? A game theory classic designed by John Nash
Gemini 3 utilizes the So Long Sucker game, a benchmark for AI deception, negotiation, and trust, originally designed by John Nash and others in 1950. The game involves four players using colored chips and requires betrayal for a player to win, enabling the assessment of AI capabilities that traditional benchmarks do not evaluate.
so-long-sucker.vercel.app
3 min
1/20/2026
How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026
Study: Self-generated Agent Skills are useless
SkillsBench is a benchmarking framework designed to evaluate the effectiveness of agent skills across 86 tasks in 11 domains. It includes curated skills and deterministic verifiers to assess their impact on large language model (LLM) agents during inference.
arxiv.org
2 min
2/16/2026
A real-world benchmark for AI code review
Qodo's code review benchmark 1.0 provides a rigorous methodology to objectively measure and validate the performance of AI-powered code review systems. The benchmark addresses limitations in existing methods that rely on backtracking from fix commits.
qodo.ai
8 min
2/4/2026
Which AI Lies Best? A game theory classic designed by John Nash
Gemini 3 utilizes the So Long Sucker game, a benchmark for AI deception, negotiation, and trust, originally designed by John Nash and others in 1950. The game involves four players using colored chips and requires betrayal for a player to win, enabling the assessment of AI capabilities that traditional benchmarks do not evaluate.
so-long-sucker.vercel.app
3 min
1/20/2026
ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
3/25/2026
Frontier AI agents violate ethical constraints 30–50% of time, pressured by KPIs
A new benchmark evaluates outcome-driven constraint violations in autonomous AI agents to enhance safety and alignment with human values. This benchmark addresses limitations of existing safety assessments that mainly focus on harmful actions.
arxiv.org
2 min
2/10/2026
Advancing AI Benchmarking with Game Arena
Google DeepMind and Kaggle launched Game Arena, a public benchmarking platform for AI models to compete in strategic games, starting with chess. The platform aims to develop AI capable of making decisions in environments with incomplete information.
blog.google
5 min
2/2/2026
How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026
Frontier AI agents violate ethical constraints 30–50% of time, pressured by KPIs
A new benchmark evaluates outcome-driven constraint violations in autonomous AI agents to enhance safety and alignment with human values. This benchmark addresses limitations of existing safety assessments that mainly focus on harmful actions.
arxiv.org
2 min
2/10/2026
Which AI Lies Best? A game theory classic designed by John Nash
Gemini 3 utilizes the So Long Sucker game, a benchmark for AI deception, negotiation, and trust, originally designed by John Nash and others in 1950. The game involves four players using colored chips and requires betrayal for a player to win, enabling the assessment of AI capabilities that traditional benchmarks do not evaluate.
so-long-sucker.vercel.app
3 min
1/20/2026
ARC-AGI-3
ARC-AGI-3 is the first interactive reasoning benchmark designed to evaluate human-like intelligence in AI agents. It requires agents to explore novel environments, acquire goals dynamically, build adaptable world models, and learn continuously, with a perfect score indicating performance that matches or exceeds human efficiency in every game.
arcprize.org
1 min
3/25/2026
A real-world benchmark for AI code review
Qodo's code review benchmark 1.0 provides a rigorous methodology to objectively measure and validate the performance of AI-powered code review systems. The benchmark addresses limitations in existing methods that rely on backtracking from fix commits.
qodo.ai
8 min
2/4/2026
Study: Self-generated Agent Skills are useless
SkillsBench is a benchmarking framework designed to evaluate the effectiveness of agent skills across 86 tasks in 11 domains. It includes curated skills and deterministic verifiers to assess their impact on large language model (LLM) agents during inference.
arxiv.org
2 min
2/16/2026
Advancing AI Benchmarking with Game Arena
Google DeepMind and Kaggle launched Game Arena, a public benchmarking platform for AI models to compete in strategic games, starting with chess. The platform aims to develop AI capable of making decisions in environments with incomplete information.
blog.google
5 min
2/2/2026
No more articles to load