Running Gemma 4 locally with LM Studio's new headless CLI and Claude Code
ai.georgeliu.com
April 5, 2026
20 min read
🔥🔥🔥🔥🔥
65/100
Summary
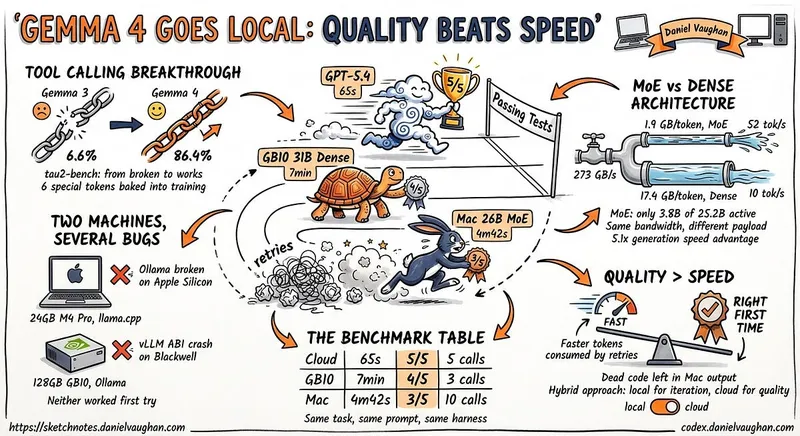
LM Studio 0.4.0 introduces llmster and the lms CLI for running Google Gemma 4 26B locally on macOS. Local inference provides advantages such as avoiding cloud API rate limits, reducing costs, enhancing privacy, and minimizing network latency.
Key Takeaways
- LM Studio 0.4.0 introduced a headless CLI and the llmster inference engine, allowing local model execution without a graphical interface.
- Google’s Gemma 4 26B model utilizes a mixture-of-experts architecture, activating only a fraction of its parameters per forward pass, enabling efficient local inference on standard hardware.
- The Gemma 4 model family includes variants optimized for different hardware, with the 31B dense model achieving high benchmark scores while the 26B-A4B model offers competitive performance with lower memory requirements.
- Running local models eliminates issues related to cloud AI APIs, such as rate limits and privacy concerns, providing cost-effective and consistent availability for tasks like code review and prompt testing.
Community Sentiment
Positives
- The introduction of a headless CLI for running Gemma 4 locally enhances accessibility for developers, enabling more users to leverage advanced AI capabilities.
- Using Claude Code as a frontend for Gemma 4 indicates a growing interest in user-friendly interfaces for AI models, which could lead to broader adoption.
Concerns
- Anthropic's cautious approach to updates suggests a reluctance to fully embrace broader applications of their models, potentially limiting innovation and flexibility for users.
- The clarification on MoE's memory usage highlights a misconception about its efficiency, indicating that users may not fully understand the implications of model architecture on resource consumption.