Apertus – Open Foundation Model for Sovereign AI
apertvs.ai
June 21, 2026
1 min read
🔥🔥🔥🔥🔥
53/100
Summary
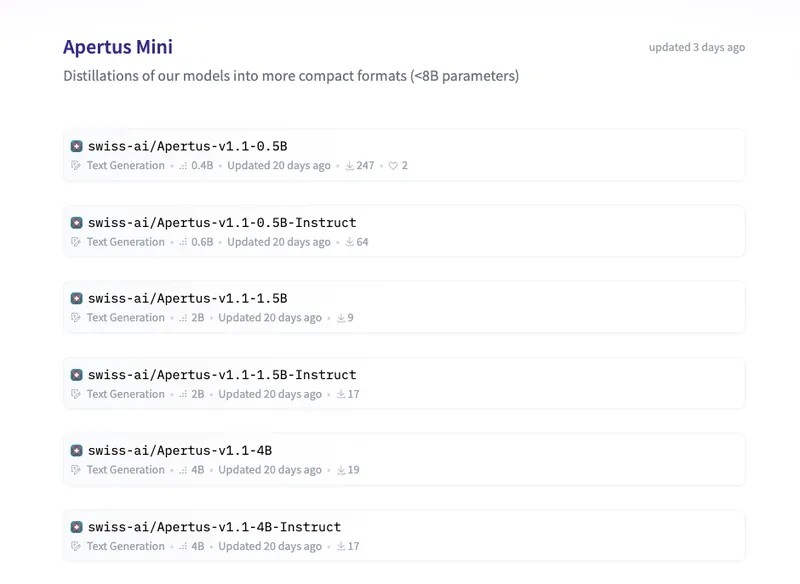
Apertus Mini consists of 16 small language models that showcase distillation and quantization techniques. Developed by the Swiss AI Initiative, the models are fully open with documented training data, code, weights, and alignment principles, and are designed to comply with EU AI Act requirements by respecting opt-outs, removing PII, and preventing memorization.
Key Takeaways
- Apertus Mini consists of 16 small language models that showcase distillation and quantization techniques.
- The models are developed by the Swiss AI Initiative in collaboration with EPFL, ETH Zurich, and CSCS, featuring open weights, data, and methods.
- Apertus Mini complies with EU AI Act requirements, including opt-out features and the removal of personally identifiable information (PII).
- The models are competitive with leading open models, available in 8B and 70B parameter versions, and trained on over 1000 languages.
Community Sentiment
Positives
- The movement towards fully open LLMs is encouraging, as it enables community contributions and transparency in AI development.
- Open pipelines for AI models can empower the community to innovate and improve upon existing technologies, fostering a more collaborative environment.
- The focus on tech sovereignty is increasingly relevant, as it highlights the need for secure data handling outside of the US.
Concerns
- Current open-weight models may not lead to the next generation of LLMs, as they are often at the mercy of frontier labs for access to state-of-the-art technologies.
- The previous version of the model has been criticized for not adhering to copyright laws, raising concerns about its reliability and usefulness.
- The model's performance in multilingual tasks is disappointing, as it frequently hallucinates incorrect information and struggles with basic language queries.