Better Models: Worse Tools

lucumr.pocoo.org
July 4, 2026
10 min read
🔥🔥🔥🔥🔥
47/100
Summary
Newer Claude models, such as Opus 4.8, sometimes generate extra, invented fields in the nested edits[] array when calling Pi's edit tool. This results in mismatched arguments that cause Pi to reject the tool call and request a retry.
Key Takeaways
- Newer Anthropic models, such as Opus 4.8 and Sonnet 5, produce malformed tool calls more frequently than older models, leading to rejected requests due to invented fields in the arguments.
- The Pi edit tool's validation fails when the model emits arguments that do not match the expected schema, resulting in errors and the need for the model to retry the tool call.
- The model's ability to generate valid tool calls is influenced by its training on specific formats, but without constraints, it may produce incorrect or extraneous keys in the output.
- Grammar-aware decoding could potentially improve the model's output by preventing it from generating invalid keys that violate the expected structure of tool calls.
Community Sentiment
Positives
- Models are proving reliable with curl commands, offering a clear separation for agents — this kind of clarity is a game changer for serverless integrations.
- The skills documentation is human-readable, providing a double win for usability and transparency in machine instructions.
- Implementing patch functionalities has shown promise, with one user praising their system prompt's effectiveness in generating better outputs.
Concerns
- Models struggle with generating proper diffs, with users noting a consistent failure to produce line numbers — this is a major headache for developers relying on precise outputs.
- There's a real concern that hyper-targeting harnesses to specific models leads to non-transferable sessions, locking developers into specific behaviors that may not be ideal.
- The potential for silent downgrades in model performance remains a troubling issue, raising questions about reliability across different domains and APIs.
Related Articles
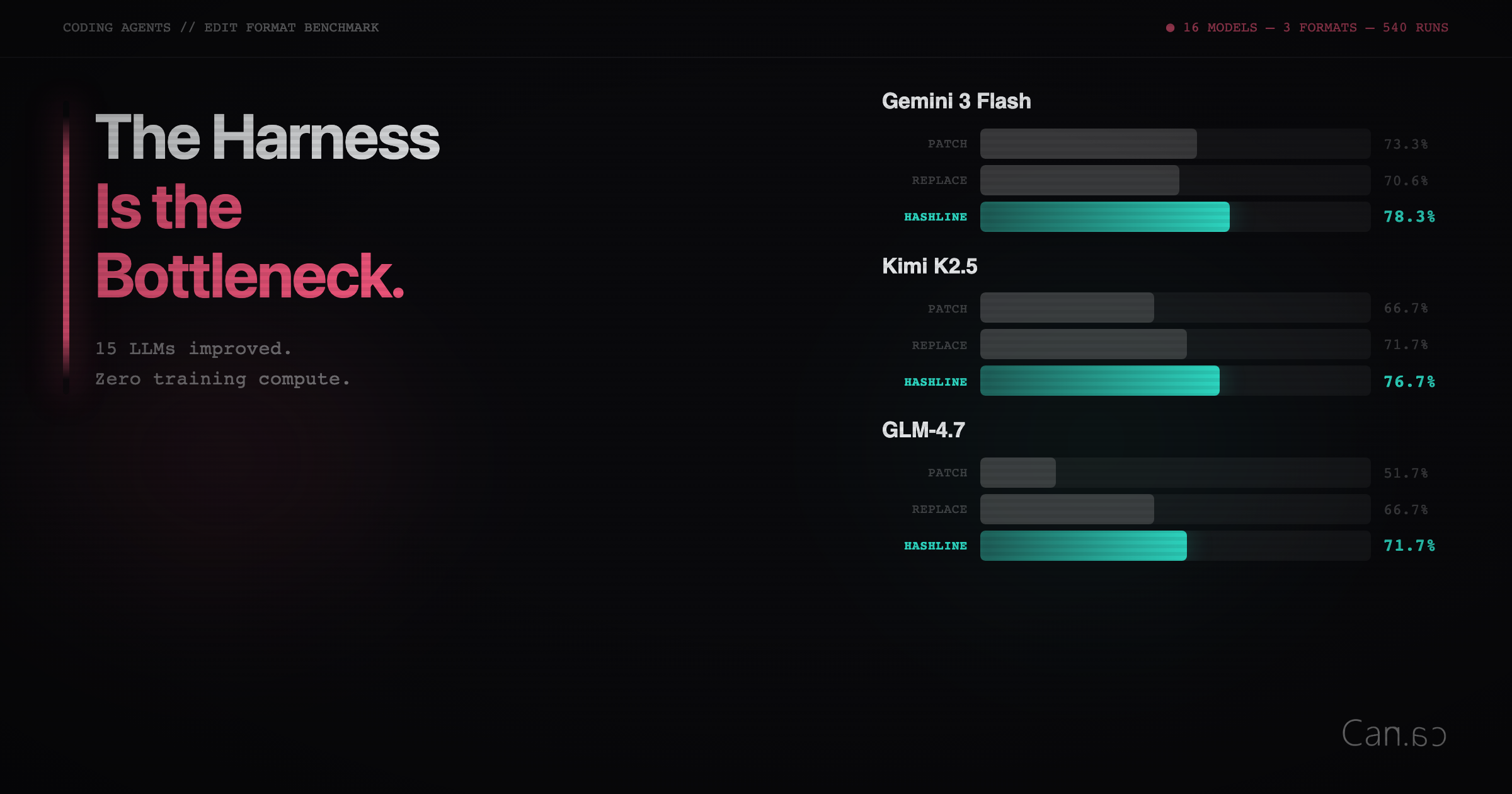
Improving 15 LLMs at Coding in One Afternoon. Only the Harness Changed
Feb 12, 2026

Why Developers Keep Choosing Claude over Every Other AI
Feb 26, 2026
DeepSeek V4 Pro at 5% the cost of Claude – what it takes to close the gap
Jun 16, 2026

Over-editing refers to a model modifying code beyond what is necessary
Apr 22, 2026

Teaching Claude Why
May 8, 2026