Improving 15 LLMs at Coding in One Afternoon. Only the Harness Changed
blog.can.ac
February 12, 2026
8 min read
🔥🔥🔥🔥🔥
73/100
Summary
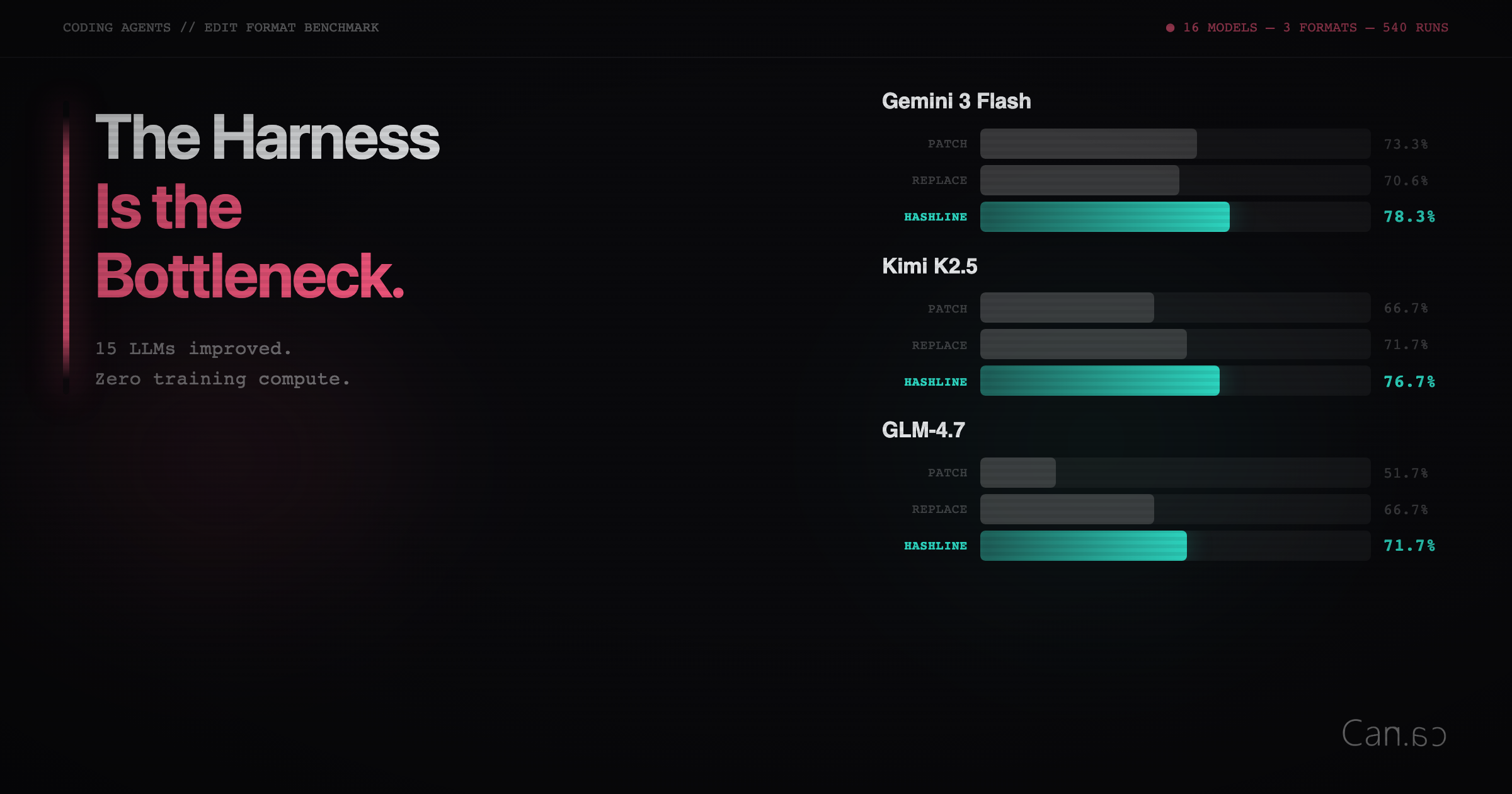
Improving coding performance in 15 language models can be achieved by changing the harness used, rather than the models themselves. The harness affects the efficiency and effectiveness of the models, highlighting its role as a critical factor in AI coding capabilities.
Key Takeaways
- The performance of large language models (LLMs) in coding tasks is significantly influenced by the harness used, rather than just the model itself.
- Different models exhibit varying patch failure rates due to their inability to conform to specific input structures, with Grok 4 and GLM-4.7 showing failure rates of 50.7% and 46.2%, respectively.
- The choice of edit format can drastically affect model performance, as demonstrated by Aider's benchmarks, which showed GPT-4 Turbo's success rate increasing from 26% to 59% based on format choice.
- There is no consensus on the best editing solution for LLMs, as evidenced by the Diff-XYZ benchmark, which found no single edit format that dominates across all models and use cases.
Community Sentiment
Positives
- Improving agent harnesses can significantly enhance the effectiveness of existing models, suggesting that design optimizations may yield greater returns than training new models.
- The article highlights the potential for harness-level improvements to reduce token waste, which could lead to more efficient AI applications.
- The distinction between the model and the harness emphasizes that effective AI deployment requires careful engineering at the interface, not just advanced model capabilities.
- The CORE benchmark example illustrates how switching harnesses can dramatically improve model performance, reinforcing the importance of harness design.