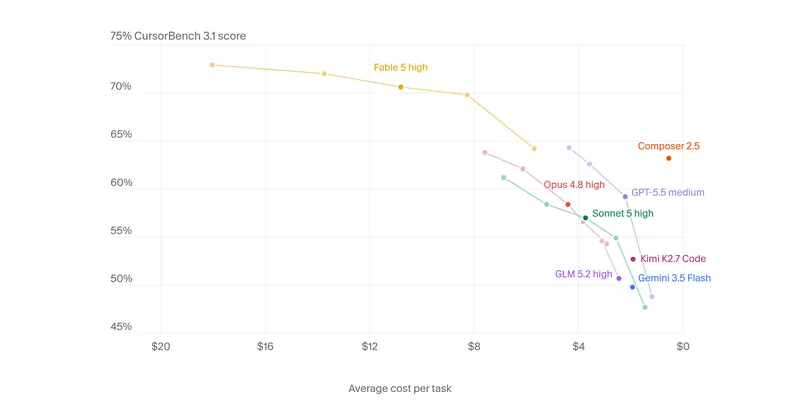
CursorBench 3.1
cursor.com
July 2, 2026
3 min read
🔥🔥🔥🔥🔥
48/100
Summary
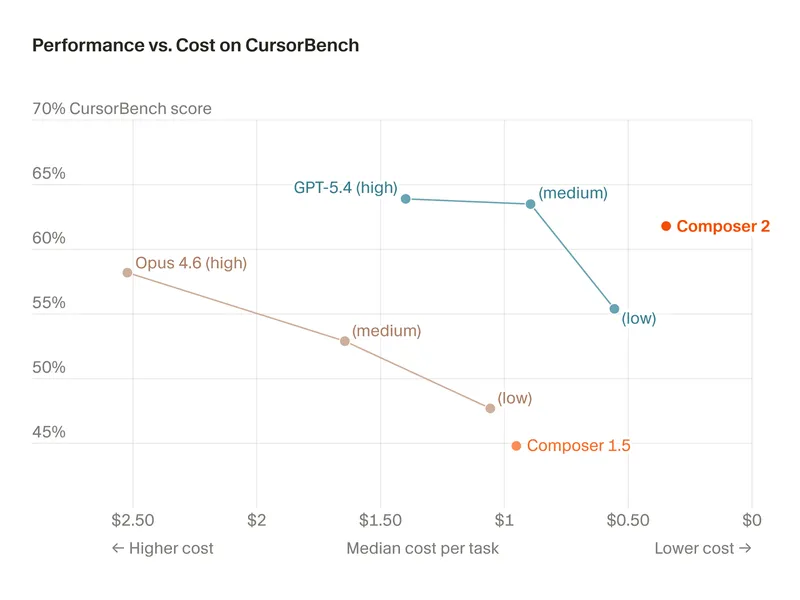
CursorBench 3.1 evaluates AI agents on ambiguous, multi-file tasks based on real Cursor sessions, with scores indicating performance. Fable 5 Max achieved the highest score of 72.9%, while GPT-5.5 Extra High scored 64.3%.
Key Takeaways
- CursorBench 3.1 evaluates AI agents on ambiguous, multi-file tasks, with Fable 5 Max achieving the highest score of 72.9%.
- The evaluation includes new tasks focused on codebase understanding, bugfinding, planning, and code review.
- Average cost per task is calculated based on each model's pricing for token usage during the evaluation.
- Results from the benchmarks are subject to variance, indicating that small score differences may not be statistically significant.
Community Sentiment
Positives
- Composer 2.5 shows promise by outperforming DeepSeek v4 Pro in the DeepSWE benchmark, indicating it has potential for specific use cases despite skepticism.
- Some users report that Composer 2.5 performs well for their tasks, suggesting it can be effective in certain scenarios, even if not universally praised.
Concerns
- Cursor's benchmark claims Composer 2.5 is comparable to top models, but independent tests reveal it significantly lags behind, raising concerns about benchmark integrity.
- Users express frustration with Composer 2.5's critical reasoning abilities, indicating it struggles with complex problem-solving compared to other models.
- The cost structure and benchmarking axes used by Cursor are deemed unintuitive, which could mislead users about the model's true performance and value.