
Political bias in AI: Where the AI models stand
Major AI models were tested with the same political, economic, and societal questions while web search was disabled. The results were mapped to reveal the inherent biases of each model, highlighting their leanings in relation to charged topics.
trakkr.ai
4 min
6/25/2026

How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026

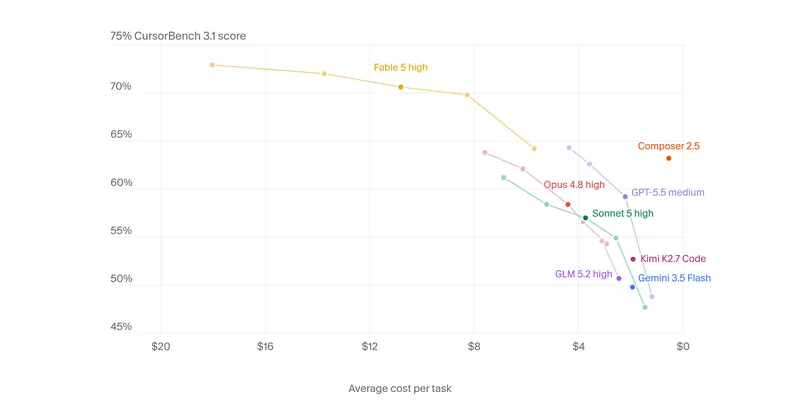
CursorBench 3.1
CursorBench 3.1 evaluates AI agents on ambiguous, multi-file tasks based on real Cursor sessions, with scores indicating performance. Fable 5 Max achieved the highest score of 72.9%, while GPT-5.5 Extra High scored 64.3%.
cursor.com
3 min
7/2/2026
How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026
Political bias in AI: Where the AI models stand
Major AI models were tested with the same political, economic, and societal questions while web search was disabled. The results were mapped to reveal the inherent biases of each model, highlighting their leanings in relation to charged topics.
trakkr.ai
4 min
6/25/2026
CursorBench 3.1
CursorBench 3.1 evaluates AI agents on ambiguous, multi-file tasks based on real Cursor sessions, with scores indicating performance. Fable 5 Max achieved the highest score of 72.9%, while GPT-5.5 Extra High scored 64.3%.
cursor.com
3 min
7/2/2026
Political bias in AI: Where the AI models stand
Major AI models were tested with the same political, economic, and societal questions while web search was disabled. The results were mapped to reveal the inherent biases of each model, highlighting their leanings in relation to charged topics.
trakkr.ai
4 min
6/25/2026
How We Broke Top AI Agent Benchmarks: And What Comes Next
Automated scanning reveals that top AI models frequently achieve high benchmark scores that do not accurately reflect their capabilities. The reliance on these benchmarks has led to a misrepresentation of model performance in the AI industry.
rdi.berkeley.edu
18 min
4/11/2026
No more articles to load