FrontierCode

cognition.ai
June 8, 2026
13 min read
🔥🔥🔥🔥🔥
60/100
Summary
FrontierCode is a new benchmark designed to evaluate the quality of AI-generated code in production environments. It aims to raise standards beyond mere correctness to assess models' ability to produce high-quality code.
Key Takeaways
- FrontierCode is a new benchmark that measures the quality of AI-generated code, focusing on code mergeability and adherence to high standards of production codebases.
- The benchmark was developed by over 20 open-source maintainers who created realistic coding tasks, with each task requiring more than 40 hours of effort.
- The best-performing model, Claude Opus 4.8, achieved a score of only 13.4% on the most difficult subset, FrontierCode Diamond, indicating that current models struggle to meet high-quality coding standards.
- FrontierCode reports metrics based on pass rates and scores, with solutions failing if they do not clear all blocker criteria, and the scoring system is designed to reflect the quality of code as defined by human maintainers.
Community Sentiment
Positives
- The introduction of 3000 rubrics for code quality represents a significant advancement in evaluating AI-generated code, potentially leading to better integration in real-world projects.
- The effort to capture over 1000 hours of real-life software maintainer work in a structured dataset demonstrates a commitment to creating more relevant and practical AI tools for developers.
- The focus on reducing false positive rates by 81% indicates a strong improvement in the reliability of AI-generated code, which is crucial for maintaining code quality in production environments.
- The collaborative nature of the evaluation process, involving expert open-source maintainers, enriches the dataset and enhances the credibility of the benchmarks established.
Concerns
- Concerns about the lack of standardization in testing methods raise questions about the reliability of the benchmarks, as model performance can vary significantly based on the evaluation tools used.
- Skepticism about the definition of 'correct' code highlights the ongoing challenges in establishing universally accepted metrics for code quality, especially for AI-generated outputs.
- Doubts regarding the potential dominance of AI-generated code in production environments suggest a fear of over-reliance on AI, which could undermine human oversight and creativity in software development.
Related Articles

DeepSWE: A contamination-free benchmark for long-horizon coding agents
May 26, 2026

We tasked Opus 4.6 using agent teams to build a C Compiler
Feb 5, 2026

Why SWE-bench Verified no longer measures frontier coding capabilities
Apr 26, 2026
Laguna S 2.1
Jul 21, 2026
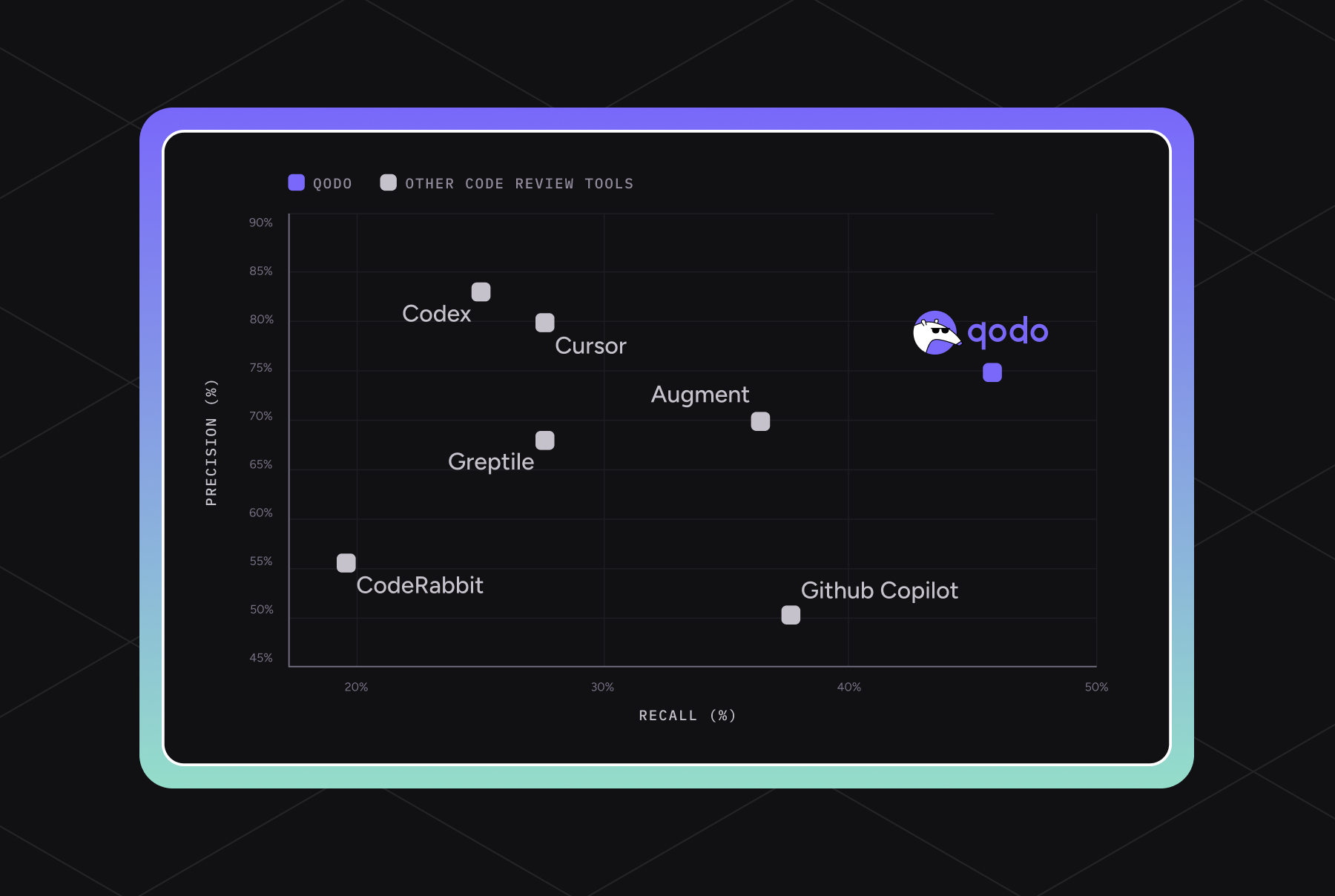
A real-world benchmark for AI code review
Feb 4, 2026