Kimi K2.6 just beat Claude, GPT-5.5, and Gemini in a coding challenge

thinkpol.ca
May 3, 2026
7 min read
🔥🔥🔥🔥🔥
64/100
Summary
Kimi K2.6, an open-weights model from Chinese startup Moonshot AI, won the AI Coding Contest's Word Gem Puzzle challenge with 22 match points and a record of 7 wins and 1 loss. It outperformed Claude, GPT-5.5, and Gemini in the competition.
Key Takeaways
- Kimi K2.6, an open-weights model from Moonshot AI, won a programming challenge with 22 match points, outperforming models like GPT-5.5 and Claude Opus 4.7.
- The programming challenge involved a sliding-tile letter puzzle, where models scored points based on the length of valid English words formed.
- MiMo V2-Pro from Xiaomi placed second with 20 match points, while GPT-5.5 ranked third with 16 match points.
- The competition featured nine models, with all Western models finishing below the top two Chinese models.
Community Sentiment
Positives
- Kimi K2.6's performance in coding challenges indicates it is competitive with leading models, suggesting a shift towards open-source solutions that can rival proprietary ones.
- The open nature of Kimi K2.6 allows for more affordable coding plans, making advanced AI accessible to users with limited hardware resources.
- The trend towards objectively scored tests in AI models is promising, as it can lead to more reliable comparisons and improvements in model performance.
- Open weight models like Kimi K2.6 are expected to inspire new product development and infrastructure, enhancing the overall AI ecosystem.
Concerns
- Concerns about the 'enshittification' of frontier models highlight the risk of performance degradation over time, emphasizing the need for stable open-weight models.
- Kimi K2.6's slower performance compared to some competitors raises questions about its viability for certain applications, despite its competitive coding capabilities.
- The subjective nature of benchmarks makes it difficult to definitively compare models, leading to confusion and frustration among users trying to find the best fit for their needs.
Related Articles

GLM 5.2 beats Claude in our benchmarks
Jun 28, 2026

GLM 5.2 vs. Opus
Jun 22, 2026
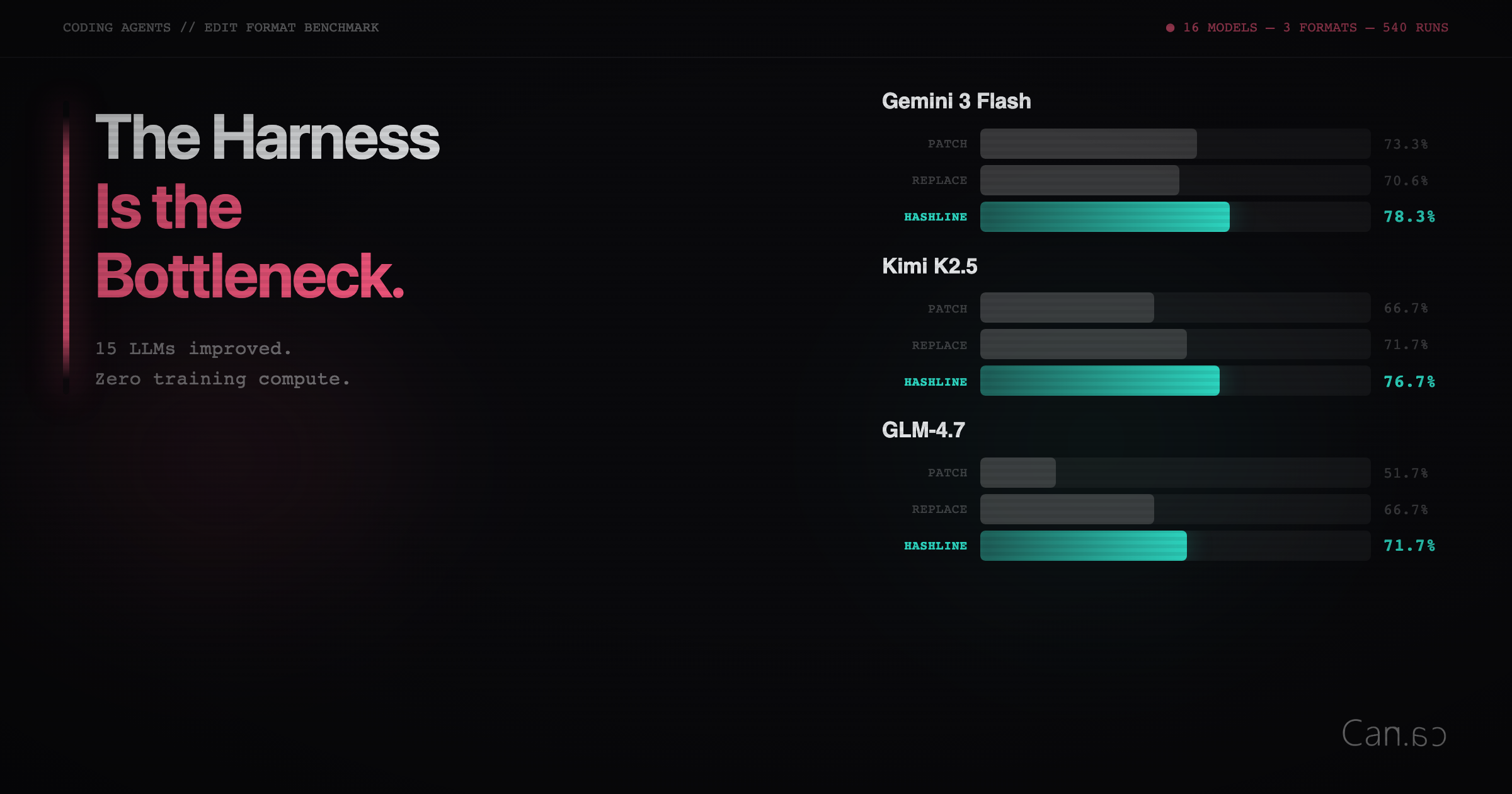
Improving 15 LLMs at Coding in One Afternoon. Only the Harness Changed
Feb 12, 2026

A robot is sprinting towards you. Do you want it running on Claude or Grok?
Jun 17, 2026

Fable 5 vs. GPT-5.6 Sol on an NP-Hard Problem: Does /goal help?
Jul 18, 2026