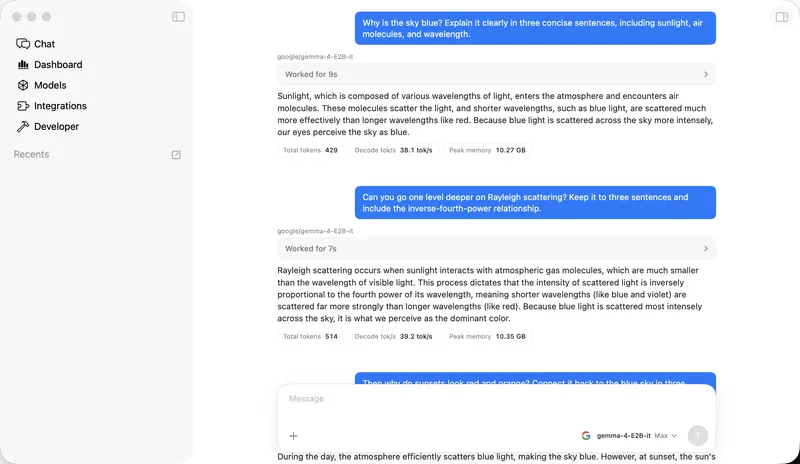
Nativ: Run frontier open models locally on your Mac
Nativ enables users to run standout open AI models from Google, Cohere, and Liquid AI on Apple Silicon without the need for accounts, subscriptions, or cloud services. The platform recommends the optimal model based on the user's hardware specifications.
blaizzy.github.io
2 min
7/20/2026
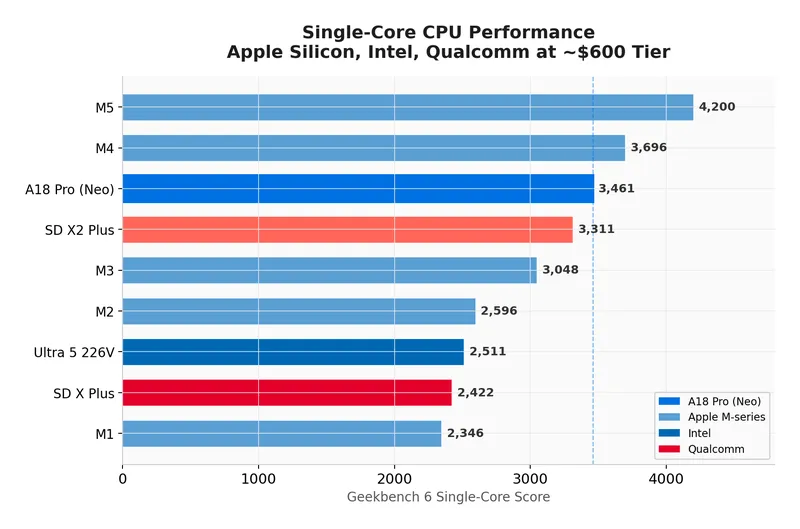
MacBook Neo Deep Dive: Benchmarks, Wafer Economics, and the 8GB Gamble
Benchmark tests reveal that the A18 Pro CPU outperforms both the M1 and M4 processors in various performance metrics. The MacBook Neo features significant advancements in processing power and efficiency, reflecting Apple's ongoing innovation in silicon design.
jdhodges.com
21 min
5/13/2026

Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026

Darkbloom – Private inference on idle Macs
Darkbloom is a decentralized inference network that utilizes idle Apple Silicon machines for private AI inference. It offers OpenAI-compatible APIs and can reduce costs by up to 70% compared to centralized alternatives while ensuring that operators cannot observe inference data.
darkbloom.dev
4 min
4/16/2026

April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026
TurboQuant KV Compression and SSD Expert Streaming for M5 Pro and IOS
SharpAI's SwiftLM is a native MLX inference server optimized for Apple Silicon, utilizing Metal and Swift for performance. It features an OpenAI-compatible API, supports SSD streaming for 100B+ MoE models, and enables direct loading of HuggingFace format models without a Python runtime.
github.com
7 min
4/2/2026

Ollama is now powered by MLX on Apple Silicon in preview
Ollama is now powered by MLX on Apple Silicon, offering significantly improved performance for applications on macOS. This enhancement accelerates personal assistants like OpenClaw and coding agents such as Claude Code and OpenCode.
ollama.com
3 min
3/31/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026

Nvidia PersonaPlex 7B on Apple Silicon: Full-Duplex Speech-to-Speech in Swift
NVIDIA PersonaPlex 7B enables full-duplex speech-to-speech communication on Apple Silicon, allowing simultaneous listening and speaking. The qwen3-asr-swift library processes audio in real-time, streaming generated audio chunks without a multi-step pipeline.
blog.ivan.digital
5 min
3/5/2026

NanoClaw moved from Apple Containers to Docker
NanoClaw transitioned from using Apple Containers to Docker to better accommodate its growing user base and support production workloads. The shift reflects the project's evolution from a personal initiative to a widely adopted tool for businesses.
twitter.com
1 min
2/22/2026
Nativ: Run frontier open models locally on your Mac
Nativ enables users to run standout open AI models from Google, Cohere, and Liquid AI on Apple Silicon without the need for accounts, subscriptions, or cloud services. The platform recommends the optimal model based on the user's hardware specifications.
blaizzy.github.io
2 min
7/20/2026
Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026
April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026
Ollama is now powered by MLX on Apple Silicon in preview
Ollama is now powered by MLX on Apple Silicon, offering significantly improved performance for applications on macOS. This enhancement accelerates personal assistants like OpenClaw and coding agents such as Claude Code and OpenCode.
ollama.com
3 min
3/31/2026
Nvidia PersonaPlex 7B on Apple Silicon: Full-Duplex Speech-to-Speech in Swift
NVIDIA PersonaPlex 7B enables full-duplex speech-to-speech communication on Apple Silicon, allowing simultaneous listening and speaking. The qwen3-asr-swift library processes audio in real-time, streaming generated audio chunks without a multi-step pipeline.
blog.ivan.digital
5 min
3/5/2026
MacBook Neo Deep Dive: Benchmarks, Wafer Economics, and the 8GB Gamble
Benchmark tests reveal that the A18 Pro CPU outperforms both the M1 and M4 processors in various performance metrics. The MacBook Neo features significant advancements in processing power and efficiency, reflecting Apple's ongoing innovation in silicon design.
jdhodges.com
21 min
5/13/2026
Darkbloom – Private inference on idle Macs
Darkbloom is a decentralized inference network that utilizes idle Apple Silicon machines for private AI inference. It offers OpenAI-compatible APIs and can reduce costs by up to 70% compared to centralized alternatives while ensuring that operators cannot observe inference data.
darkbloom.dev
4 min
4/16/2026
TurboQuant KV Compression and SSD Expert Streaming for M5 Pro and IOS
SharpAI's SwiftLM is a native MLX inference server optimized for Apple Silicon, utilizing Metal and Swift for performance. It features an OpenAI-compatible API, supports SSD streaming for 100B+ MoE models, and enables direct loading of HuggingFace format models without a Python runtime.
github.com
7 min
4/2/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026
NanoClaw moved from Apple Containers to Docker
NanoClaw transitioned from using Apple Containers to Docker to better accommodate its growing user base and support production workloads. The shift reflects the project's evolution from a personal initiative to a widely adopted tool for businesses.
twitter.com
1 min
2/22/2026
Nativ: Run frontier open models locally on your Mac
Nativ enables users to run standout open AI models from Google, Cohere, and Liquid AI on Apple Silicon without the need for accounts, subscriptions, or cloud services. The platform recommends the optimal model based on the user's hardware specifications.
blaizzy.github.io
2 min
7/20/2026
Darkbloom – Private inference on idle Macs
Darkbloom is a decentralized inference network that utilizes idle Apple Silicon machines for private AI inference. It offers OpenAI-compatible APIs and can reduce costs by up to 70% compared to centralized alternatives while ensuring that operators cannot observe inference data.
darkbloom.dev
4 min
4/16/2026
Ollama is now powered by MLX on Apple Silicon in preview
Ollama is now powered by MLX on Apple Silicon, offering significantly improved performance for applications on macOS. This enhancement accelerates personal assistants like OpenClaw and coding agents such as Claude Code and OpenCode.
ollama.com
3 min
3/31/2026
NanoClaw moved from Apple Containers to Docker
NanoClaw transitioned from using Apple Containers to Docker to better accommodate its growing user base and support production workloads. The shift reflects the project's evolution from a personal initiative to a widely adopted tool for businesses.
twitter.com
1 min
2/22/2026
MacBook Neo Deep Dive: Benchmarks, Wafer Economics, and the 8GB Gamble
Benchmark tests reveal that the A18 Pro CPU outperforms both the M1 and M4 processors in various performance metrics. The MacBook Neo features significant advancements in processing power and efficiency, reflecting Apple's ongoing innovation in silicon design.
jdhodges.com
21 min
5/13/2026
April 2026 TLDR Setup for Ollama and Gemma 4 26B on a Mac mini
Ollama can be installed on a Mac mini with Apple Silicon using Homebrew with the command `brew install --cask ollama-app`, which includes auto-updates and the MLX backend. A minimum of 16GB of unified memory is required for running Gemma 4, and the Ollama app will appear in the Applications folder and the menu bar after installation.
gist.github.com
4 min
4/3/2026
Run a 1T parameter model on a 32gb Mac by streaming tensors from NVMe
Hypura is a storage-tier-aware LLM inference scheduler designed for Apple Silicon, allowing users to run large models that exceed their Mac's memory. It optimally distributes model tensors across GPU, RAM, and NVMe storage based on access patterns and hardware capabilities to prevent system crashes.
github.com
6 min
3/24/2026
Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026
TurboQuant KV Compression and SSD Expert Streaming for M5 Pro and IOS
SharpAI's SwiftLM is a native MLX inference server optimized for Apple Silicon, utilizing Metal and Swift for performance. It features an OpenAI-compatible API, supports SSD streaming for 100B+ MoE models, and enables direct loading of HuggingFace format models without a Python runtime.
github.com
7 min
4/2/2026
Nvidia PersonaPlex 7B on Apple Silicon: Full-Duplex Speech-to-Speech in Swift
NVIDIA PersonaPlex 7B enables full-duplex speech-to-speech communication on Apple Silicon, allowing simultaneous listening and speaking. The qwen3-asr-swift library processes audio in real-time, streaming generated audio chunks without a multi-step pipeline.
blog.ivan.digital
5 min
3/5/2026
No more articles to load