
RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026

Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026

Taking on CUDA with ROCm: 'One Step After Another'
AMD's ROCm software stack aims to compete with Nvidia's CUDA for data center GPU market share. Success in this endeavor is viewed as a significant challenge due to CUDA's established dominance.
eetimes.com
6 min
4/12/2026

MegaTrain: Full Precision Training of 100B+ Parameter LLMs on a Single GPU
MegaTrain is a memory-centric system that enables the full precision training of large language models with over 100 billion parameters on a single GPU. It utilizes host memory to store parameters and optimizer states, treating GPUs as transient computation units.
arxiv.org
2 min
4/8/2026
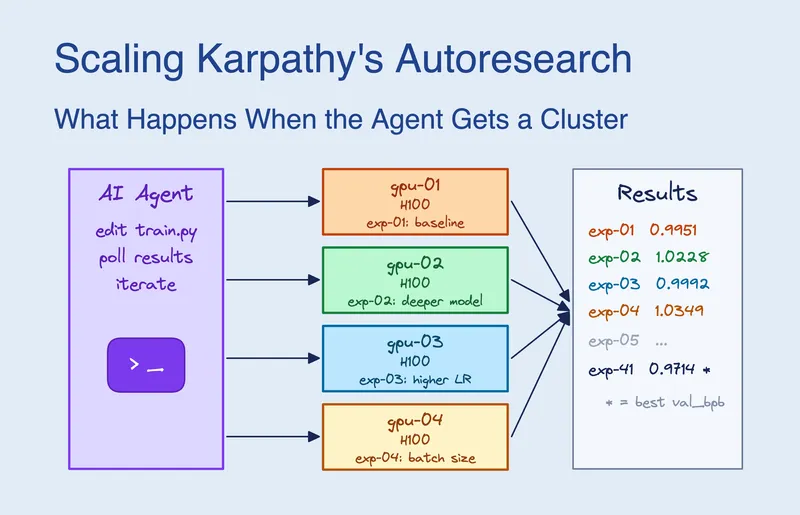
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
A CPU that runs entirely on GPU
nCPU is a CPU architecture that operates entirely on GPU, utilizing tensors for registers, memory, flags, and the program counter. All arithmetic operations, including addition, multiplication, bitwise operations, and shifts, are performed through trained neural networks, with specific methods like Kogge-Stone carry-lookahead for addition and learned byte-pair lookup tables for multiplication.
github.com
8 min
3/4/2026
RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026
Taking on CUDA with ROCm: 'One Step After Another'
AMD's ROCm software stack aims to compete with Nvidia's CUDA for data center GPU market share. Success in this endeavor is viewed as a significant challenge due to CUDA's established dominance.
eetimes.com
6 min
4/12/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026
MegaTrain: Full Precision Training of 100B+ Parameter LLMs on a Single GPU
MegaTrain is a memory-centric system that enables the full precision training of large language models with over 100 billion parameters on a single GPU. It utilizes host memory to store parameters and optimizer states, treating GPUs as transient computation units.
arxiv.org
2 min
4/8/2026
A CPU that runs entirely on GPU
nCPU is a CPU architecture that operates entirely on GPU, utilizing tensors for registers, memory, flags, and the program counter. All arithmetic operations, including addition, multiplication, bitwise operations, and shifts, are performed through trained neural networks, with specific methods like Kogge-Stone carry-lookahead for addition and learned byte-pair lookup tables for multiplication.
github.com
8 min
3/4/2026
RTX 5080 and RTX 3090 Setup: 80 Tok/s on Qwen 3.6 27B Q8
An RTX 5080 and RTX 3090 setup achieves over 80 tokens per second on the Qwen 3.6 27B Q8 model. The RTX 3090, with 24GB of memory, significantly enhances performance, allowing for initial speeds of 30 tokens per second, increasing to 50-60 tokens per second with MTP.
imil.net
5 min
6/13/2026
MegaTrain: Full Precision Training of 100B+ Parameter LLMs on a Single GPU
MegaTrain is a memory-centric system that enables the full precision training of large language models with over 100 billion parameters on a single GPU. It utilizes host memory to store parameters and optimizer states, treating GPUs as transient computation units.
arxiv.org
2 min
4/8/2026
Zero-Copy GPU Inference from WebAssembly on Apple Silicon
WebAssembly modules on Apple Silicon can share linear memory directly with the GPU, eliminating the need for copies, serialization, or intermediate buffers. This allows the CPU and GPU to read and write the same physical bytes, enabling efficient end-to-end computation without serialization overhead.
abacusnoir.com
7 min
4/18/2026
Scaling Karpathy's Autoresearch: What Happens When the Agent Gets a GPU Cluster
Claude Code was given access to 16 GPUs on a Kubernetes cluster and submitted approximately 910 experiments over 8 hours. It determined that scaling model width was more significant than any single hyperparameter and achieved a 2.87% improvement in validation performance, reducing val_bpb from 1.003 to 0.974.
blog.skypilot.co
12 min
3/19/2026
Taking on CUDA with ROCm: 'One Step After Another'
AMD's ROCm software stack aims to compete with Nvidia's CUDA for data center GPU market share. Success in this endeavor is viewed as a significant challenge due to CUDA's established dominance.
eetimes.com
6 min
4/12/2026
A CPU that runs entirely on GPU
nCPU is a CPU architecture that operates entirely on GPU, utilizing tensors for registers, memory, flags, and the program counter. All arithmetic operations, including addition, multiplication, bitwise operations, and shifts, are performed through trained neural networks, with specific methods like Kogge-Stone carry-lookahead for addition and learned byte-pair lookup tables for multiplication.
github.com
8 min
3/4/2026
No more articles to load