$500 GPU outperforms Claude Sonnet on coding benchmarks
github.com
March 26, 2026
8 min read
🔥🔥🔥🔥🔥
67/100
Summary
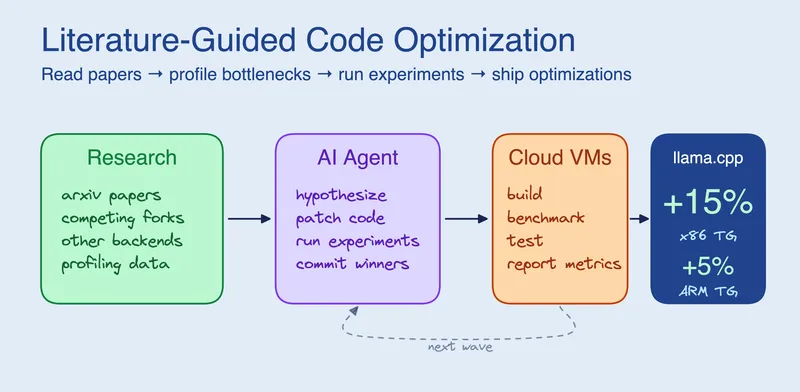
A.T.L.A.S achieves a 74.6% pass rate on LiveCodeBench with a frozen 14B model using a single consumer GPU, significantly improving from the previous 36-41% in V2. The system utilizes constraint-driven generation and self-verified iterative refinement, allowing a smaller model to compete with larger models at a reduced cost without fine-tuning.
Key Takeaways
- A.T.L.A.S achieves a 74.6% pass rate on the LiveCodeBench benchmark using a frozen 14B model on a single consumer GPU, significantly improving from 36-41% in the previous version.
- The system operates fully self-hosted, requiring no fine-tuning, API calls, or cloud services, ensuring that no data leaves the machine.
- A.T.L.A.S utilizes a pipeline involving constraint-driven generation and self-verified iterative refinement to compete with leading API models at a lower cost.
- The estimated cost per task for A.T.L.A.S is approximately $0.004, compared to $0.043 for GPT-5 and $0.002 for DeepSeek V3.2.
Community Sentiment
Positives
- The $500 GPU's performance surpassing Claude Sonnet on coding benchmarks indicates a significant advancement in cost-effective AI solutions, potentially democratizing access to powerful tools.
- Optimizing apps and prompts to manage reasoning budgets can lead to substantial savings, highlighting the importance of strategic resource management in AI applications.
- The excitement around the potential of slimming down models suggests a trend towards more efficient AI, which could enhance accessibility and usability in various domains.
Concerns
- Higher reasoning token use and slower outputs in some models indicate that cost-effective solutions may come with trade-offs in performance, which could limit their practical applications.
- Concerns about the practical utility of models that pass benchmarks but fail in real-world scenarios emphasize the need for robust evaluation beyond just performance metrics.
- The skepticism regarding whether open-source or local LLMs can compete with major AI providers reflects uncertainty about the future landscape of AI development and market dynamics.