Can LLMs model real-world systems in TLA+?
sigops.org
May 8, 2026
10 min read
52/100
Summary
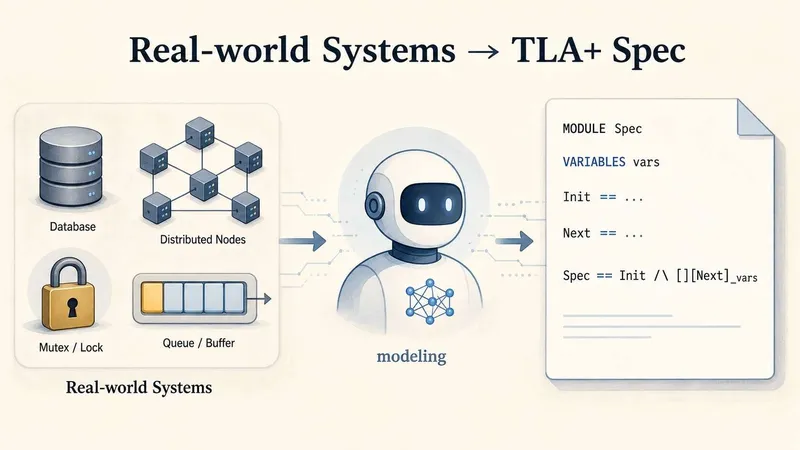
LLMs can be evaluated for their ability to model system code using TLA+, a specification language for concurrent and distributed systems. The Specula team explored using Claude to create a TLA+ specification for Etcd.
Key Takeaways
- LLMs can generate TLA+ specifications that pass syntax checks and run without errors, but struggle with accurately modeling specific systems.
- The SysMoBench benchmark evaluates LLM-generated TLA+ specs across four phases: syntax, runtime, conformance, and invariant, revealing significant gaps in modeling accuracy.
- Leading LLMs average around 46% on conformance and 41% on invariant scores, indicating systematic failures in accurately reflecting real-world system behaviors.
- Common failure modes include generating specifications that enter unreachable states or fail to reach states that should always be accessible in the actual system.
Community Sentiment
Positives
- Claude's ability to model systems in TLA+ has improved significantly, showcasing advancements in LLM capabilities for formal verification tasks.
- The progress in Claude's modeling of complex systems like Monopoly indicates a rapid enhancement in LLM performance, which could streamline specification writing in the future.
Concerns
- There are concerns about the validity of LLM-generated TLA+ models, as users question whether these models can truly capture human intent and design.
- The reliance on LLMs for generating both design and implementation raises doubts about the assurance of correctness, as users may not fully understand or specify their requirements.
Related Articles

LLM Neuroanatomy II: Modern LLM Hacking and Hints of a Universal Language?
Mar 24, 2026

Reliable Software in the LLM Era
Mar 12, 2026

Leanstral: Open-Source foundation for trustworthy vibe-coding
Mar 16, 2026

AI OSS tool repo goes archived over night after raising $7.3M Seed
Jun 13, 2026
Anthropic researchers detail “model spec midtraining”, which adds a stage between pretraining and fine-tuning to improve generalization from alignment training
May 7, 2026