How to setup a local coding agent on macOS

ikyle.me
June 12, 2026
9 min read
🔥🔥🔥🔥🔥
67/100
Summary
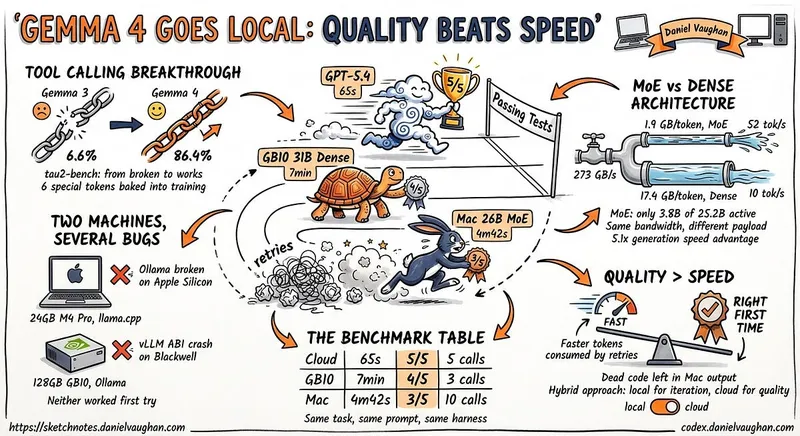
Gemma 4 26B-A4B and Qwen3.6 35B-A3B can be run locally on macOS using llama.cpp, MTP speculative decoding, and multimodal support. The setup aims to provide a fast and reliable local coding agent to avoid interruptions from internet failures.
Key Takeaways
- The local coding agent setup on macOS utilizes Gemma 4 26B-A4B and Qwen3.6 with llama.cpp, achieving usable speeds for coding tasks.
- The Gemma 4 model with Multi-Token Prediction (MTP) improved generation speed by approximately 24%, reaching 72.2 tokens per second.
- The optimal configuration for MTP on an Apple M1 Max was found to be using 3 draft tokens, balancing speed and performance.
- The complete model setup requires about 17 GB of storage, including the main model and MTP draft model.
Community Sentiment
Positives
- Using omlx.ai has streamlined the process of downloading and launching multiple models, enhancing the user experience for local AI on macOS.
- The responsiveness of the developers behind the local inference tools is commendable, indicating a strong commitment to improving the open-source project.
- Running local models can provide privacy and reliability, making them a viable alternative to AI-as-a-Service solutions.
Concerns
- Local models often struggle with performance compared to hosted solutions, leading to frustration for users who invest time and resources.
- Benchmarking with only 128 tokens is insufficient for evaluating model performance, risking misleading conclusions about speed and efficiency.
- There is a lack of focus on the quality of outputs in local AI discussions, with many prioritizing speed over the usefulness of generated content.