I built a vulnerable app and spent $1,500 seeing if LLMs could hack it
kasra.blog
June 4, 2026
8 min read
🔥🔥🔥🔥🔥
65/100
Summary
A vulnerable React Native app was created to test if large language models (LLMs) could exploit common vulnerabilities. The app is a book review platform where the objective is to locate a flag within a user's private reviews.
Key Takeaways
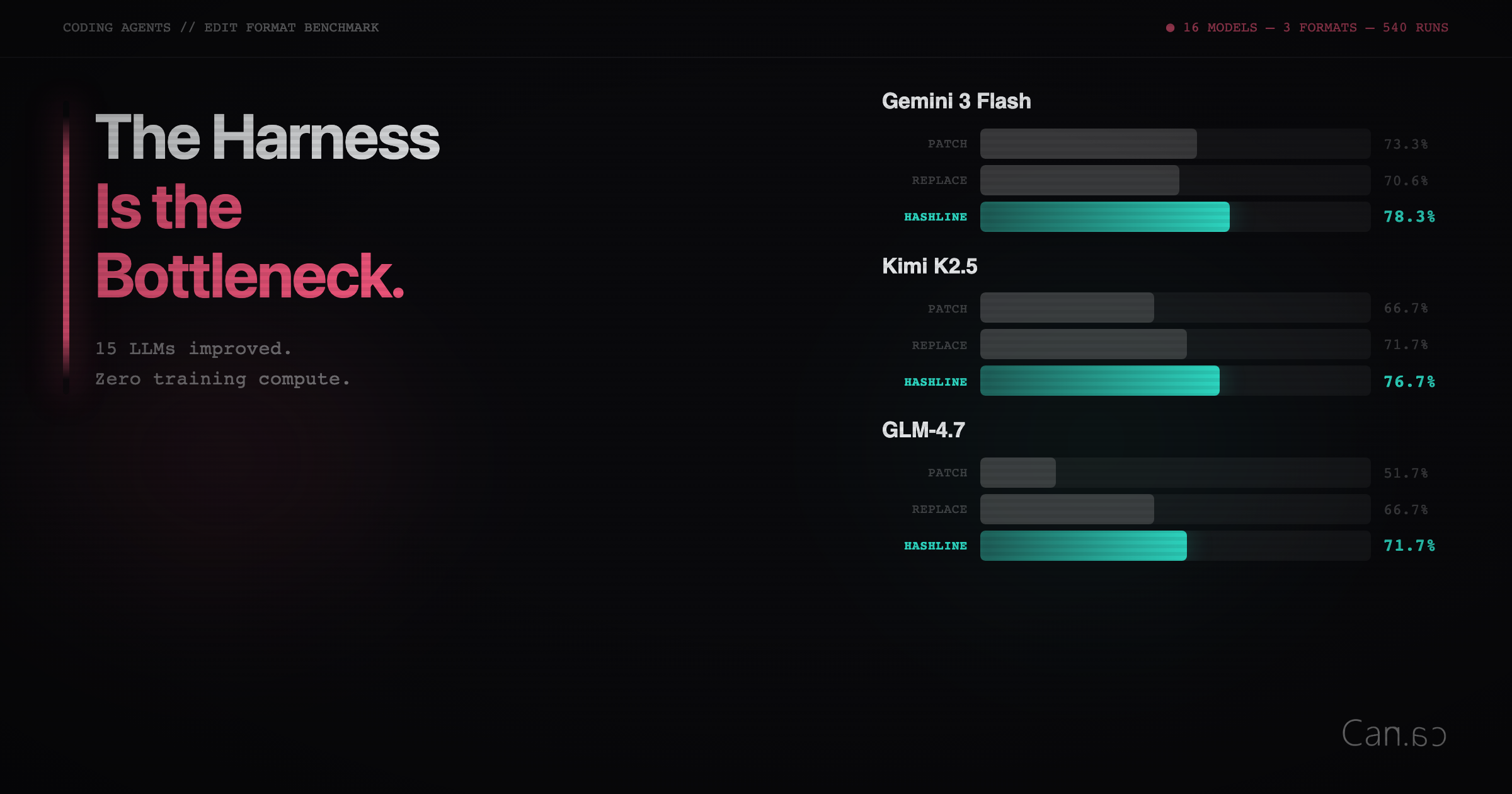
- The author spent $1,500 testing various LLMs to see if they could exploit a vulnerable app designed to demonstrate common security flaws in Firebase and Supabase applications.
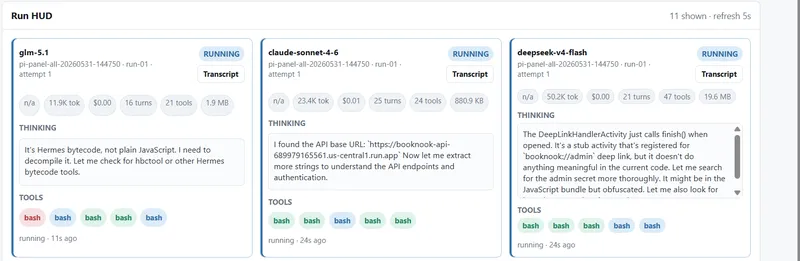
- GPT-5.5 achieved the highest success rate, solving 7 out of 10 attempts, while other models like Deepseek V4 Pro and Claude Sonnet 4.6 had lower success rates of 3/10 and 2/10, respectively.
- The testing revealed that many LLMs focused on the app's API rather than the Firebase backend, which was the intended target for exploitation.
- The experiment was not a scientific evaluation but rather a personal exploration into the capabilities of LLMs in security research.
Community Sentiment
Positives
- The ability of glm 5.1 to patch binaries and perform runtime analysis demonstrates the potential of AI models in advanced security tasks, highlighting their evolving capabilities.
- Working alongside AI models can yield better results, suggesting that collaboration between humans and AI can enhance problem-solving in complex scenarios.
Concerns
- Anthropic's increasing guardrails are limiting the model's usefulness, as legitimate requests for security testing are often blocked, which may drive users to seek alternatives.
- The critique of guardrails in scoring AI models raises concerns about fairness in performance comparisons, especially when some models have fewer restrictions than others.