LLM Architecture Gallery

sebastianraschka.com
March 15, 2026
8 min read
🔥🔥🔥🔥🔥
69/100
Summary
The LLM Architecture Gallery compiles architecture figures and fact sheets from significant LLM comparisons. Users can enlarge figures and navigate to corresponding sections using model titles.
Key Takeaways
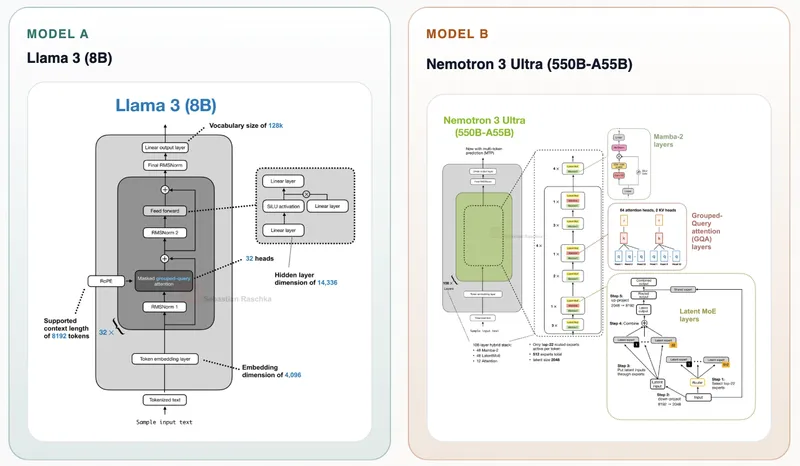
- The Llama 3 model features 8 billion parameters and utilizes a dense decoder with GQA and RoPE attention mechanisms, focusing on a pre-norm baseline.
- The DeepSeek V3 model has a total of 671 billion parameters, employing a sparse MoE decoder and MLA attention, with a training recipe oriented towards reasoning.
- Gemma 3 is designed with 27 billion parameters and emphasizes local attention, utilizing a sliding-window/global attention strategy for multilingual capabilities.
- The GPT-OSS 120B model maintains an alternating attention structure similar to its 20B counterpart, scaled up for OpenAI's flagship open-weight release.
Community Sentiment
Positives
- The presentation of LLM architectures is visually appealing and reminiscent of the Neural Network Zoo, which effectively showcases different models.
- A modular approach to understanding neural networks could greatly benefit practitioners by bridging theoretical concepts with real-world applications.
Concerns
- There is a desire for more structured information, such as a family tree of LLM evolution, indicating a lack of clarity in the current presentation.

![[AINews] Why OpenAI Should Build Slack](https://substackcdn.com/image/fetch/$s_!XQAE!,w_1200,h_675,c_fill,f_jpg,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F89ee056a-0ea2-4473-8e1c-9b21f034c717_1474x2116.png)