DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
lmsys.org
April 25, 2026
17 min read
🔥🔥🔥🔥🔥
48/100
Summary
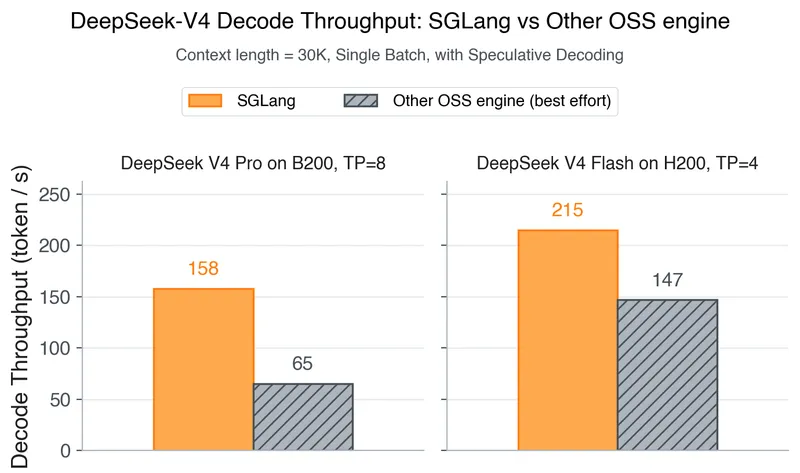
DeepSeek-V4 is now supported for both inference and reinforcement learning (RL) training from Day 0. SGLang and Miles provide the first open-source stack designed for DeepSeek-V4’s hybrid sparse-attention architecture and manifold-constrained hyper-connections, utilizing FP4 expert weights.
Key Takeaways
- DeepSeek-V4 features Day-0 support for both inference and reinforcement learning training, utilizing SGLang and Miles as the first open-source stack for its launch.
- The model incorporates hybrid sparse-attention, manifold-constrained hyper-connections (mHC), and FP4 expert weights for enhanced performance and efficiency.
- DeepSeek-V4 supports a 1M-token context window by combining sliding window attention with two compression mechanisms, allowing for efficient processing of large inputs.
- The ShadowRadix caching mechanism enables coherent management of multiple heterogeneous key-value pools, optimizing the handling of hybrid attention across layers.
Related Articles

Bringing Up DeepSeek-V4-Flash on AMD MI300X
Jun 2, 2026

DeepSeek V4–almost on the frontier, a fraction of the price
May 1, 2026
DeepSeek 4 Flash local inference engine for Metal
May 7, 2026

LLM Neuroanatomy II: Modern LLM Hacking and Hints of a Universal Language?
Mar 24, 2026

Open Reproduction of DeepSeek-R1
Jun 11, 2026