Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
blog.kog.ai
May 29, 2026
18 min read
🔥🔥🔥🔥🔥
58/100
Summary
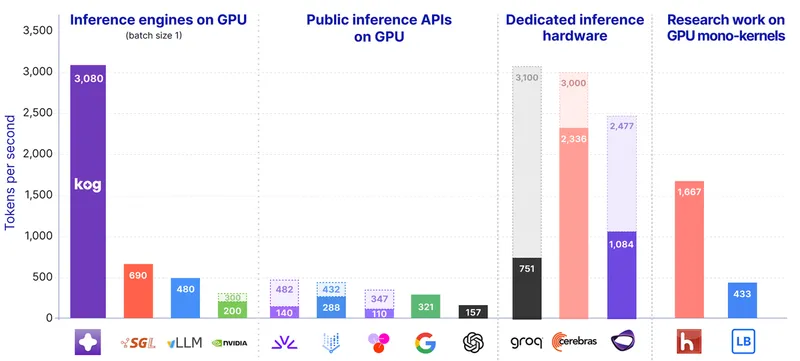
Kog AI has launched a tech preview of the Kog Inference Engine (KIE), achieving 3,000 output tokens per second on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 GPUs using FP16 without speculative decoding. The preview currently supports a 2B model, with plans to add support for large third-party MoE models at similar speeds.
Key Takeaways
- Kog AI launched the Kog Inference Engine (KIE), achieving 3,000 output tokens per second on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 GPUs.
- The primary bottleneck for fast token generation on GPUs is memory bandwidth, which limits decoding speed during autoregressive decoding.
- Optimizing single-request latency is crucial for AI agents, as it significantly impacts user experience and productivity in iterative workflows.
- The KIE tech preview demonstrates that standard datacenter GPUs can achieve speeds comparable to dedicated inference hardware by optimizing the software stack.
Community Sentiment
Positives
- Achieving 3k tokens per second on standard GPUs opens up exciting possibilities for real-time applications, making advanced AI more accessible.
- The demo showcases the potential for rapid inference, hinting at future advancements in AI capabilities and user experiences.
- The focus on standard GPUs rather than custom chips suggests a push towards democratizing access to powerful AI tools.
Concerns
- The comparison of a 2B model against much larger frontier models raises concerns about the fairness and relevance of the benchmarks presented.
- Some users feel that the term 'standard GPUs' is misleading, as it primarily refers to high-end data center GPUs rather than consumer-grade hardware.
- The performance of the small model in the demo has been criticized for lacking depth, indicating limitations in its practical applications.



![[AINews] Why OpenAI Should Build Slack](https://substackcdn.com/image/fetch/$s_!XQAE!,w_1200,h_675,c_fill,f_jpg,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F89ee056a-0ea2-4473-8e1c-9b21f034c717_1474x2116.png)