Performance per dollar is getting faster and cheaper

wafer.ai
July 3, 2026
5 min read
🔥🔥🔥🔥🔥
59/100
Summary
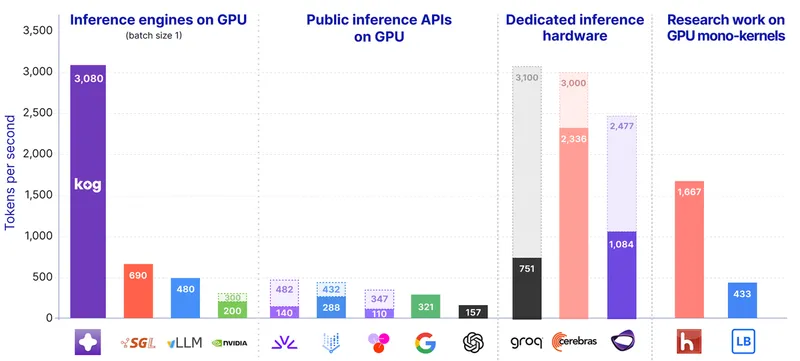
Performance per dollar for AI inference is improving, with GLM5.2 served on AMD MI355X achieving 2626 tokens per second per node and 213 tokens per second in a single stream at over 2x lower cost than Blackwell. Demand for inference is increasing rapidly, outpacing supply, as new frontier models are released frequently.
Key Takeaways
- AMD MI355X provides over 2x lower cost for inference compared to NVIDIA Blackwell while achieving a throughput of 2626 tok/s/node.
- The demand for AI inference is increasing rapidly, outpacing supply and causing NVIDIA GPU prices to rise.
- AMD's MI350 series competes with NVIDIA at the silicon level but lacks the same level of software support, which can delay performance optimization for new models.
- Wafer achieved 213 tok/s on GLM5.2 using AMD MI355X, demonstrating better performance per dollar despite not topping the leaderboard.
Community Sentiment
Positives
- There's a growing interest in AMD's performance per watt, which could shake up the data center landscape, especially for companies outside the US where energy costs are a major factor.
- The mention of companies like Meta and OpenAI using AMD is a promising sign that they might finally be gaining traction against Nvidia's dominance.
Concerns
- Quantization to FP4 is often a disaster for accuracy, with many models losing their edge and becoming 'lobotomized' — not what we need for frontier-level AI.
- Skepticism runs high about AMD's ability to compete; many users are tired of being disappointed and doubt they'll finally see viable competition against Nvidia.