Reinforcement Learning from Human Feedback
arxiv.org
February 7, 2026
2 min read
🔥🔥🔥🔥🔥
53/100
Summary
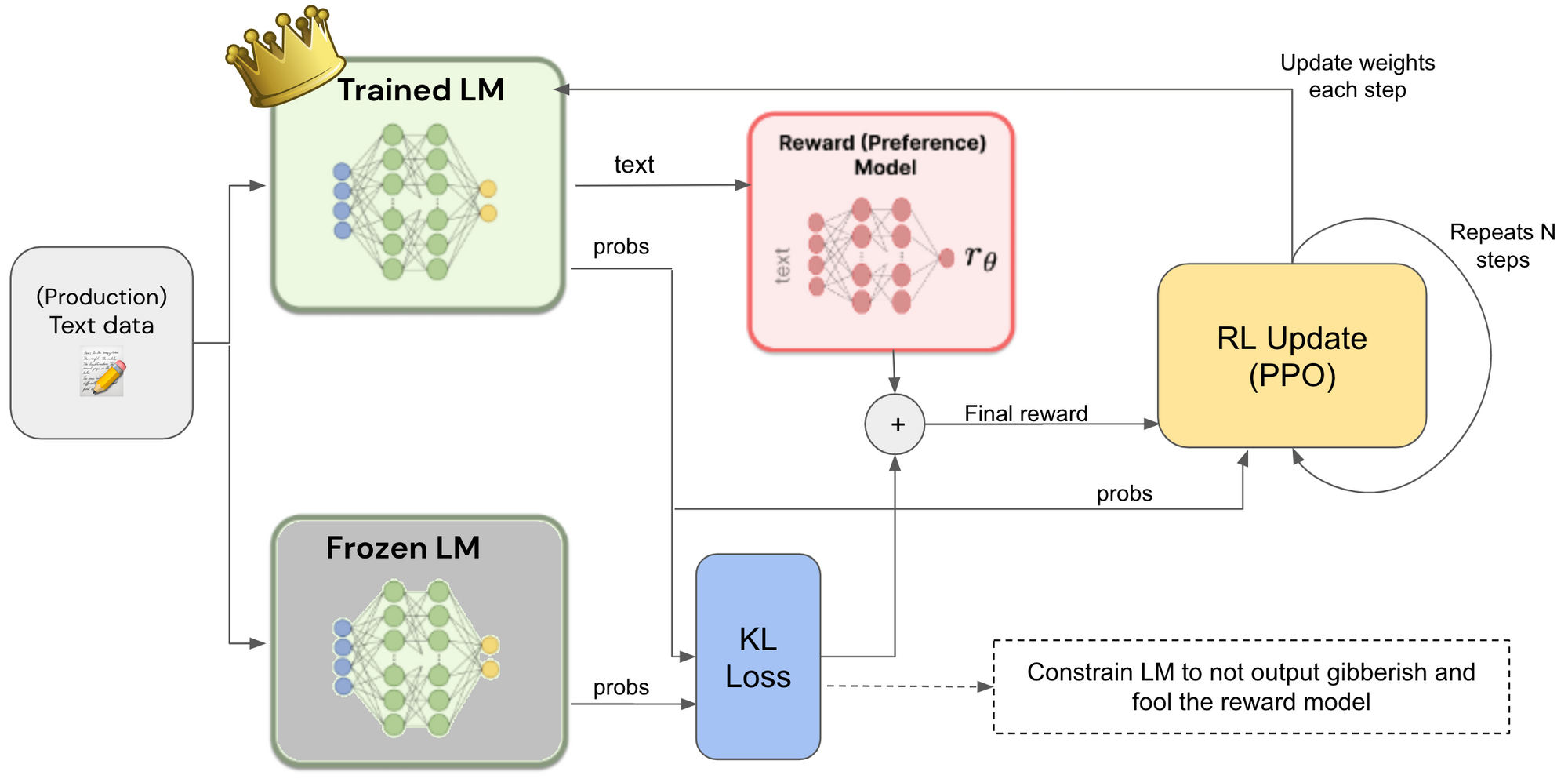
Reinforcement learning from human feedback (RLHF) is a key technique for deploying advanced machine learning systems. A new book provides an introduction to the core methods of RLHF for readers with a quantitative background.
Key Takeaways
- Reinforcement learning from human feedback (RLHF) is a critical tool for deploying advanced machine learning systems.
- The book covers the origins of RLHF, including its connections to economics, philosophy, and optimal control.
- It details the optimization stages of RLHF, including instruction tuning, reward model training, and various algorithms for alignment.
- The book concludes with discussions on advanced topics such as synthetic data, evaluation, and open research questions in the field.
Related Articles

Can LLMs Beat Classical Hyperparameter Optimization Algorithms?
Jun 9, 2026

AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights
May 2, 2026

Towards Autonomous Mathematics Research
Feb 15, 2026

Why AI systems don't learn – On autonomous learning from cognitive science
Mar 17, 2026

Mathematical methods and human thought in the age of AI
Mar 30, 2026