
Ford AI hiccups push carmaker to rehire ‘gray beard’ inspectors
Ford Motor Co. has rehired 350 veteran engineers, referred to as "gray beard" inspectors, to address quality issues and improve AI tools. These engineers are assisting in training younger staff and reprogramming the AI systems that have been ineffective.
bloomberg.com
1 min
2d ago

Meta pauses AI training program tracking employee keystrokes after internal leak
Meta has paused an internal AI training program after sensitive employee data, including private conversations and performance metrics, was leaked across the company. The incident has been classified as a SEV 2, and Meta is currently investigating the breach.
businessinsider.com
2 min
5d ago

Meta workers can opt out of being tracked at work up to 30 min
Meta is reducing its plan to track employee computer activity for AI training after receiving internal criticism. Employees can now pause data collection for up to 30 minutes at a time.
bbc.com
2 min
6/3/2026

Shift will clean homes for free to train future robots
AI startup Shift offers free home cleaning services to collect footage of cleaners in action. The recorded data will be used to train future cleaning robots.
theverge.com
2 min
5/29/2026

Norway's 2 petabytes of Huawei flash storage and LLM training
Norway's National Library is developing a large language model (LLM) for the Norwegian language using 2 petabytes of Huawei OceanStor Dorado flash storage. Marius Husnes, Head of IT Platform, stated that no commercial LLM provider is currently developing a local Norwegian language model.
blocksandfiles.com
4 min
5/25/2026

I work in Hollywood. Everyone who used to make TV is now training AI
AI trainers in Hollywood are now focusing on tasks such as assessing chatbot tone, identifying patterns in images, and annotating video content. Professionals from the television industry are shifting their skills to train AI systems for various applications.
wired.com
24 min
5/11/2026

Zuckerberg 'Personally Authorized and Encouraged' Meta's Copyright Infringement
Meta and CEO Mark Zuckerberg are facing a lawsuit from five publishers and author Scott Turow, who allege that the company illegally copied millions of copyrighted works to train its AI systems. The plaintiffs claim that Meta's actions were motivated by a desire to advance in the AI space, reflecting the company's motto of "move fast and break things."
variety.com
4 min
5/5/2026

Uber wants to turn its drivers into a sensor grid for self-driving companies
Uber plans to equip its human drivers' vehicles with sensors to collect real-world data for autonomous vehicle companies and other AI model training. This initiative aims to create a sensor grid leveraging the extensive network of Uber drivers.
techcrunch.com
3 min
5/2/2026

Shai-Hulud Themed Malware Found in the PyTorch Lightning AI Training Library
The PyPI package 'lightning', versions 2.6.2 and 2.6.3, was compromised in a supply chain attack, affecting users of the PyTorch Lightning AI training library. The malicious versions include a hidden _runtime directory containing obfuscated JavaScript that activates upon running pip install lightning.
semgrep.dev
6 min
4/30/2026
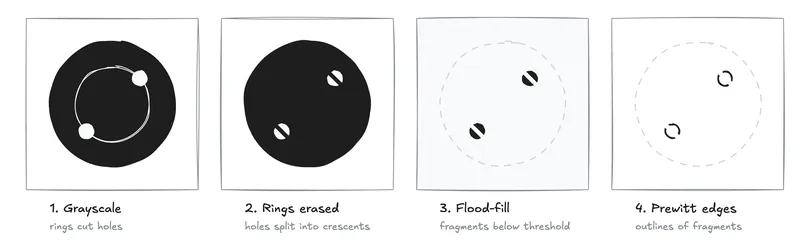
My phone replaced a brass plug
A cooking project involving venison required learning to shoot and tracking progress through the adaptation of a 2012 OpenCV paper. Training a state-of-the-art computer vision model contributed to a longer preparation time for the dinner.
drobinin.com
11 min
4/23/2026
Ford AI hiccups push carmaker to rehire ‘gray beard’ inspectors
Ford Motor Co. has rehired 350 veteran engineers, referred to as "gray beard" inspectors, to address quality issues and improve AI tools. These engineers are assisting in training younger staff and reprogramming the AI systems that have been ineffective.
bloomberg.com
1 min
2d ago
Meta workers can opt out of being tracked at work up to 30 min
Meta is reducing its plan to track employee computer activity for AI training after receiving internal criticism. Employees can now pause data collection for up to 30 minutes at a time.
bbc.com
2 min
6/3/2026
Norway's 2 petabytes of Huawei flash storage and LLM training
Norway's National Library is developing a large language model (LLM) for the Norwegian language using 2 petabytes of Huawei OceanStor Dorado flash storage. Marius Husnes, Head of IT Platform, stated that no commercial LLM provider is currently developing a local Norwegian language model.
blocksandfiles.com
4 min
5/25/2026
Zuckerberg 'Personally Authorized and Encouraged' Meta's Copyright Infringement
Meta and CEO Mark Zuckerberg are facing a lawsuit from five publishers and author Scott Turow, who allege that the company illegally copied millions of copyrighted works to train its AI systems. The plaintiffs claim that Meta's actions were motivated by a desire to advance in the AI space, reflecting the company's motto of "move fast and break things."
variety.com
4 min
5/5/2026
Shai-Hulud Themed Malware Found in the PyTorch Lightning AI Training Library
The PyPI package 'lightning', versions 2.6.2 and 2.6.3, was compromised in a supply chain attack, affecting users of the PyTorch Lightning AI training library. The malicious versions include a hidden _runtime directory containing obfuscated JavaScript that activates upon running pip install lightning.
semgrep.dev
6 min
4/30/2026
Meta pauses AI training program tracking employee keystrokes after internal leak
Meta has paused an internal AI training program after sensitive employee data, including private conversations and performance metrics, was leaked across the company. The incident has been classified as a SEV 2, and Meta is currently investigating the breach.
businessinsider.com
2 min
5d ago
Shift will clean homes for free to train future robots
AI startup Shift offers free home cleaning services to collect footage of cleaners in action. The recorded data will be used to train future cleaning robots.
theverge.com
2 min
5/29/2026
I work in Hollywood. Everyone who used to make TV is now training AI
AI trainers in Hollywood are now focusing on tasks such as assessing chatbot tone, identifying patterns in images, and annotating video content. Professionals from the television industry are shifting their skills to train AI systems for various applications.
wired.com
24 min
5/11/2026
Uber wants to turn its drivers into a sensor grid for self-driving companies
Uber plans to equip its human drivers' vehicles with sensors to collect real-world data for autonomous vehicle companies and other AI model training. This initiative aims to create a sensor grid leveraging the extensive network of Uber drivers.
techcrunch.com
3 min
5/2/2026
My phone replaced a brass plug
A cooking project involving venison required learning to shoot and tracking progress through the adaptation of a 2012 OpenCV paper. Training a state-of-the-art computer vision model contributed to a longer preparation time for the dinner.
drobinin.com
11 min
4/23/2026
Ford AI hiccups push carmaker to rehire ‘gray beard’ inspectors
Ford Motor Co. has rehired 350 veteran engineers, referred to as "gray beard" inspectors, to address quality issues and improve AI tools. These engineers are assisting in training younger staff and reprogramming the AI systems that have been ineffective.
bloomberg.com
1 min
2d ago
Shift will clean homes for free to train future robots
AI startup Shift offers free home cleaning services to collect footage of cleaners in action. The recorded data will be used to train future cleaning robots.
theverge.com
2 min
5/29/2026
Zuckerberg 'Personally Authorized and Encouraged' Meta's Copyright Infringement
Meta and CEO Mark Zuckerberg are facing a lawsuit from five publishers and author Scott Turow, who allege that the company illegally copied millions of copyrighted works to train its AI systems. The plaintiffs claim that Meta's actions were motivated by a desire to advance in the AI space, reflecting the company's motto of "move fast and break things."
variety.com
4 min
5/5/2026
My phone replaced a brass plug
A cooking project involving venison required learning to shoot and tracking progress through the adaptation of a 2012 OpenCV paper. Training a state-of-the-art computer vision model contributed to a longer preparation time for the dinner.
drobinin.com
11 min
4/23/2026
Meta pauses AI training program tracking employee keystrokes after internal leak
Meta has paused an internal AI training program after sensitive employee data, including private conversations and performance metrics, was leaked across the company. The incident has been classified as a SEV 2, and Meta is currently investigating the breach.
businessinsider.com
2 min
5d ago
Norway's 2 petabytes of Huawei flash storage and LLM training
Norway's National Library is developing a large language model (LLM) for the Norwegian language using 2 petabytes of Huawei OceanStor Dorado flash storage. Marius Husnes, Head of IT Platform, stated that no commercial LLM provider is currently developing a local Norwegian language model.
blocksandfiles.com
4 min
5/25/2026
Uber wants to turn its drivers into a sensor grid for self-driving companies
Uber plans to equip its human drivers' vehicles with sensors to collect real-world data for autonomous vehicle companies and other AI model training. This initiative aims to create a sensor grid leveraging the extensive network of Uber drivers.
techcrunch.com
3 min
5/2/2026
Meta workers can opt out of being tracked at work up to 30 min
Meta is reducing its plan to track employee computer activity for AI training after receiving internal criticism. Employees can now pause data collection for up to 30 minutes at a time.
bbc.com
2 min
6/3/2026
I work in Hollywood. Everyone who used to make TV is now training AI
AI trainers in Hollywood are now focusing on tasks such as assessing chatbot tone, identifying patterns in images, and annotating video content. Professionals from the television industry are shifting their skills to train AI systems for various applications.
wired.com
24 min
5/11/2026
Shai-Hulud Themed Malware Found in the PyTorch Lightning AI Training Library
The PyPI package 'lightning', versions 2.6.2 and 2.6.3, was compromised in a supply chain attack, affecting users of the PyTorch Lightning AI training library. The malicious versions include a hidden _runtime directory containing obfuscated JavaScript that activates upon running pip install lightning.
semgrep.dev
6 min
4/30/2026