Running local LLMs offline on a ten-hour flight

deploy.live
April 27, 2026
4 min read
🔥🔥🔥🔥🔥
53/100
Summary
A MacBook Pro M5 Max with 128GB of unified memory and a 40-core GPU was used to run local LLMs offline during a ten-hour flight. Gemma 4 31B and Qwen 4.6 36B were tested alongside the top 100 most common Docker images and programming languages, enabling the building of function sites with rich visualizations.
Key Takeaways
- A MacBook Pro M5 Max was used to run local LLMs offline during a ten-hour flight, achieving comparable output to frontier models for various engineering tasks.
- The author developed a billing analytics tool using DuckDB and custom UI, revealing patterns in cloud spending that standard dashboards did not expose.
- Significant limitations encountered included power consumption of 1% battery per minute under load, overheating issues, and degraded performance beyond 100k tokens.
- The author created two monitoring tools, powermonitor and lmstats, to track power usage and model performance during the flight.
Community Sentiment
Positives
- Qwen3.6 27B is being recognized as a consumer-grade model capable of replacing advanced workloads, indicating significant progress in local AI model capabilities.
- Local models can be tailored for specific tasks, providing users with the flexibility to optimize performance according to their needs, which is a step towards greater accessibility.
Concerns
- Many users find that local models often lead to unproductive infinite reasoning loops, suggesting that current implementations may not be robust enough for meaningful applications.
- There is skepticism about the hype surrounding local AI models, with some users feeling that they fail to deliver substantial results compared to hosted solutions.
Related Articles

Local Qwen isn't a worse Opus, it's a different tool
Jun 18, 2026
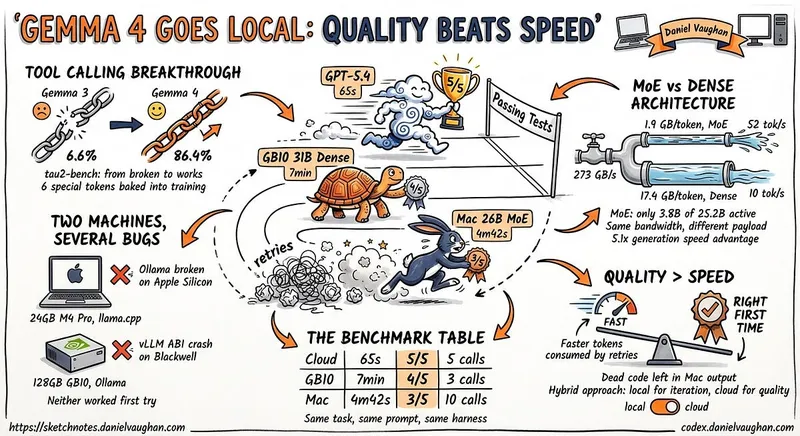
I ran Gemma 4 as a local model in Codex CLI
Apr 12, 2026

Running local models on an M4 with 24GB memory
May 10, 2026
Running Gemma 4 locally with LM Studio's new headless CLI and Claude Code
Apr 5, 2026

Qwen 3.6 27B is the sweet spot for local development
Jun 29, 2026