Is One Layer Enough? A Single Transformer Layer Matches Full-Parameter RL Train

arxiv.org
July 2, 2026
2 min read
🔥🔥🔥🔥🔥
50/100
Summary
Training a single transformer layer can achieve performance comparable to full-parameter reinforcement learning (RL) training. This finding suggests that RL adaptation may not require uniform updates across all layers of large language models.
Key Takeaways
- Training a single transformer layer can recover most of the gains achieved by full-parameter reinforcement learning (RL) training, and in some cases, it can even surpass it.
- The concept of "layer contribution" quantifies the fraction of full RL improvement recovered by training a layer in isolation.
- RL gains are highly concentrated in a small subset of transformer layers, with high-contribution layers typically located in the middle of the transformer stack.
- The layer rankings for contribution to RL gains remain consistent across different datasets, tasks, model families, and RL algorithms.
Community Sentiment
Positives
- The paper's findings suggest that a single transformer layer can effectively match the performance of full-parameter RL training, which could simplify model architectures.
- Understanding that early layers focus on syntax while middle layers manipulate concepts provides valuable insight into transformer functionality, enhancing our approach to AI model design.
- The exploration of using RL to shape high-level planning in transformer outputs indicates promising directions for improving AI's decision-making capabilities.
Concerns
- The suggestion that one layer might be sufficient for complex tasks overlooks the need for higher expressivity in models, which could limit performance in practical applications.
- Concerns arise that the proposed idea of using a single layer may not align with established practices, indicating potential gaps in the paper's conclusions.
Related Articles
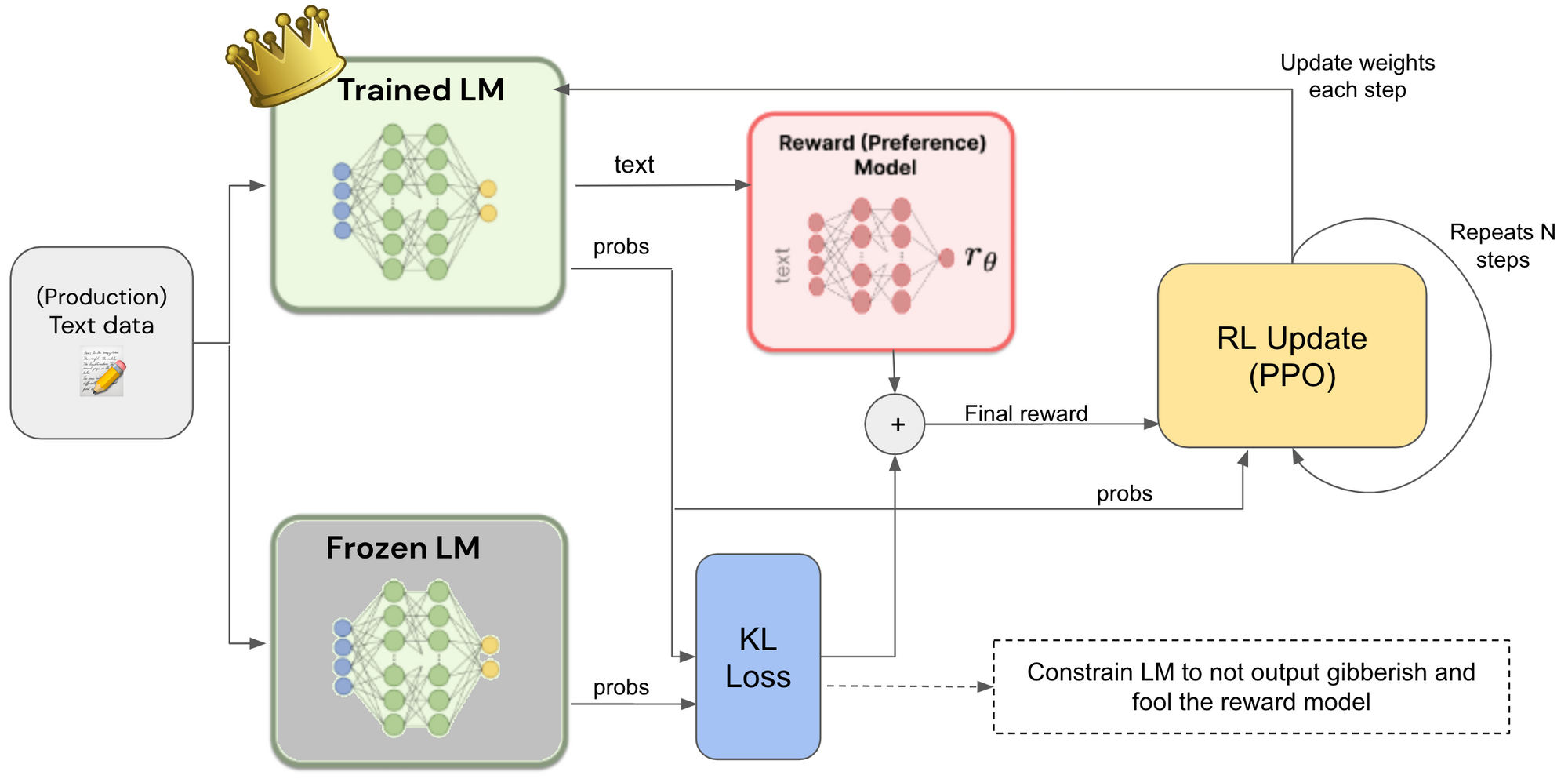
Reinforcement Learning from Human Feedback
Feb 7, 2026

A sleep-like consolidation mechanism for LLMs
May 26, 2026

Do transformers need three projections? Systematic study of QKV variants
Jun 4, 2026

Can LLMs Beat Classical Hyperparameter Optimization Algorithms?
Jun 9, 2026

David Patterson: Challenges and Research Directions for LLM Inference Hardware
Jan 25, 2026