Do transformers need three projections? Systematic study of QKV variants

arxiv.org
June 4, 2026
2 min read
🔥🔥🔥🔥🔥
59/100
Summary
Transformers utilize a query, key, and value (QKV) attention formulation that is crucial for AI tasks. The study investigates the individual contributions of these three projections and the effects of omitting any of them.
Key Takeaways
- The study evaluates three projection sharing constraints in transformers: shared key-value (Q-K=V), shared query-key (Q=K-V), and single projection (Q=K=V).
- The Q-K=V projection sharing achieves a 50% reduction in key-value cache with only a 3.1% increase in perplexity during language modeling tasks.
- Combining Q-K=V with group query attention (GQA) or multi-query attention (MQA) can yield cache reductions of 87.5% and 96.9%, respectively, facilitating practical on-device inference.
- The research systematically characterizes projection sharing as a form of weight tying in attention, providing quantifiable memory benefits for edge deployment.
Community Sentiment
Positives
- The exploration of QKV variants through ablation studies is valuable, as it can lead to insights on model simplifications that may benefit hardware-constrained environments.
- The discussion around the correlation between performance and sequence lengths for the Q-K=V model highlights important considerations for future research in transformer architectures.
Concerns
- The limited training data of 10B tokens for a 1.2B model raises concerns about the generalizability of the findings, especially when compared to modern models trained on significantly larger datasets.
- Confusing notation in the paper detracts from the clarity of the research, potentially hindering understanding and application of the proposed concepts.
Related Articles

Fast KV Compaction via Attention Matching
Feb 20, 2026

A sleep-like consolidation mechanism for LLMs
May 26, 2026

Is One Layer Enough? A Single Transformer Layer Matches Full-Parameter RL Train
Jul 2, 2026

VibeThinker: 3B param model that beats Opus 4.5 on reasoning with novel SFT+GRPO
Jun 23, 2026
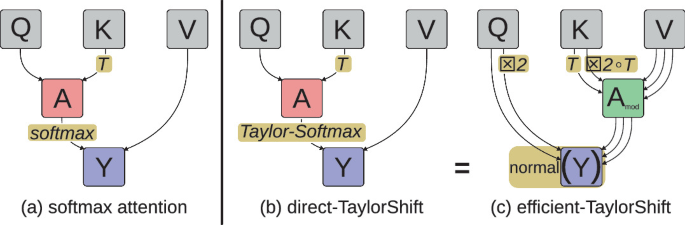
Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Feb 4, 2026