Bringing Up DeepSeek-V4-Flash on AMD MI300X

fergusfinn.com
June 2, 2026
8 min read
🔥🔥🔥🔥🔥
52/100
Summary
DeepSeek-V4-Flash is being implemented on the AMD MI300X, which launched in December 2023 as AMD's competitor to NVIDIA's H100 and H200 AI accelerators. The MI300X aims to address the current compute shortage while building an inference cloud for high-volume AI tasks.
Key Takeaways
- AMD launched the MI300X in December 2023 as a competitor to NVIDIA's H100, featuring 192GB of HBM3 memory and a list price approximately half that of the H100.
- The MI300X faces software compatibility issues, particularly with running AI workloads, which has hindered its adoption despite its strong hardware specifications.
- The MI300X utilizes a unique FP8 datatype called "fnuz," which is incompatible with the OCP-standard FP8 used by newer AMD chips, complicating its integration with existing AI frameworks.
- DeepSeek v4's attention mechanism is designed to be sparse, allowing queries to focus on a top-k subset of the KV cache, but it currently struggles with implementation on the MI300X.
Related Articles

Performance per dollar is getting faster and cheaper
Jul 3, 2026
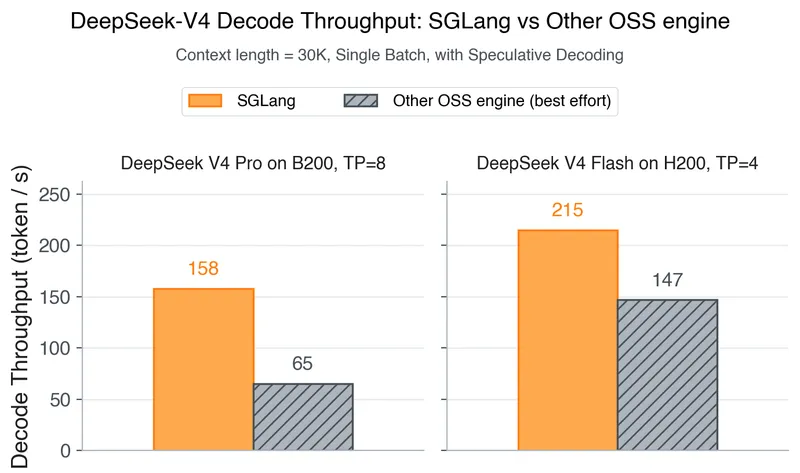
DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
Apr 25, 2026

A 10 year old Xeon is all you need
Jun 1, 2026

DeepSeek V4–almost on the frontier, a fraction of the price
May 1, 2026
Running Gemma 4 26B at 5 tokens/sec on a 13-year-old Xeon with no GPU
Jul 15, 2026