
Kimi K2.7-Code: open-source coding model with better token efficiency
moonshotai/Kimi-K2.7-Code can be utilized with libraries like Transformers for image-text-to-text tasks. A high-level pipeline can be created using the command `pipe = pipeline("image-text-to-text", model="moonshotai/Kimi-K2.7-Code", trust_remote_code=True)`.
huggingface.co
9 min
6/12/2026

Transformers Are Inherently Succinct
Transformers exhibit inherent succinctness in their representations, enabling efficient processing of information. This research has been recognized as one of three outstanding papers for ICLR 2026.
openreview.net
1 min
6/5/2026

Do transformers need three projections? Systematic study of QKV variants
Transformers utilize a query, key, and value (QKV) attention formulation that is crucial for AI tasks. The study investigates the individual contributions of these three projections and the effects of omitting any of them.
arxiv.org
2 min
6/4/2026
Soul Player C64 – A real transformer running on a 1 MHz Commodore 64
A transformer model with approximately 25,000 parameters is implemented on an unmodified Commodore 64, utilizing hand-written 6502/6510 assembly. This 2-layer decoder-only architecture features real multi-head causal self-attention, softmax, and RMSNorm, and can be loaded from a floppy disk.
github.com
5 min
4/21/2026
Attention Residuals
Attention Residuals (AttnRes) serves as a drop-in replacement for standard residual connections in Transformers, allowing each layer to selectively aggregate earlier representations. It includes two variants: Full AttnRes, where each layer attends over all previous outputs, and Block AttnRes, which groups layers into blocks to reduce memory usage from O(Ld) to O(Nd).
github.com
3 min
3/21/2026

Building a Minimal Transformer for 10-digit Addition
A minimal transformer model has been developed to perform 10-digit addition tasks. The model demonstrates the ability to learn and execute arithmetic operations effectively.
alexlitzenberger.com
1 min
2/28/2026

FORTH? Really!?
FORTH and associative/applicative languages may be more suitable for transformer architectures than traditional top-down problem-solving methods. Generating outputs before their constituent parts could enhance the effectiveness of large language models.
rescrv.net
3 min
2/6/2026
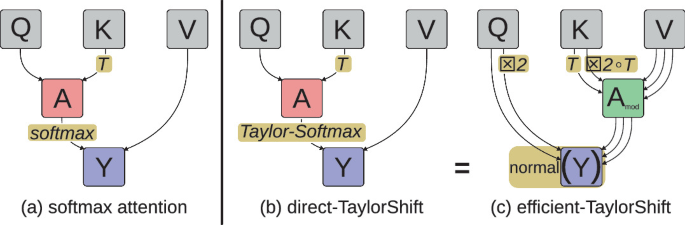
Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Self-attention mechanisms in Transformers typically incur costs that increase with context length, leading to higher demands for storage, compute, and energy. A new method using symmetry-aware Taylor approximation aims to maintain constant cost per token for self-attention, potentially alleviating these resource demands.
arxiv.org
2 min
2/4/2026

David Patterson: Challenges and Research Directions for LLM Inference Hardware
Large Language Model (LLM) inference faces significant challenges primarily related to memory and interconnect issues rather than compute power. The autoregressive Decode phase of Transformer models distinguishes LLM inference from training, complicating the process.
arxiv.org
2 min
1/25/2026
Kimi K2.7-Code: open-source coding model with better token efficiency
moonshotai/Kimi-K2.7-Code can be utilized with libraries like Transformers for image-text-to-text tasks. A high-level pipeline can be created using the command `pipe = pipeline("image-text-to-text", model="moonshotai/Kimi-K2.7-Code", trust_remote_code=True)`.
huggingface.co
9 min
6/12/2026
Do transformers need three projections? Systematic study of QKV variants
Transformers utilize a query, key, and value (QKV) attention formulation that is crucial for AI tasks. The study investigates the individual contributions of these three projections and the effects of omitting any of them.
arxiv.org
2 min
6/4/2026
Attention Residuals
Attention Residuals (AttnRes) serves as a drop-in replacement for standard residual connections in Transformers, allowing each layer to selectively aggregate earlier representations. It includes two variants: Full AttnRes, where each layer attends over all previous outputs, and Block AttnRes, which groups layers into blocks to reduce memory usage from O(Ld) to O(Nd).
github.com
3 min
3/21/2026
FORTH? Really!?
FORTH and associative/applicative languages may be more suitable for transformer architectures than traditional top-down problem-solving methods. Generating outputs before their constituent parts could enhance the effectiveness of large language models.
rescrv.net
3 min
2/6/2026
David Patterson: Challenges and Research Directions for LLM Inference Hardware
Large Language Model (LLM) inference faces significant challenges primarily related to memory and interconnect issues rather than compute power. The autoregressive Decode phase of Transformer models distinguishes LLM inference from training, complicating the process.
arxiv.org
2 min
1/25/2026
Transformers Are Inherently Succinct
Transformers exhibit inherent succinctness in their representations, enabling efficient processing of information. This research has been recognized as one of three outstanding papers for ICLR 2026.
openreview.net
1 min
6/5/2026
Soul Player C64 – A real transformer running on a 1 MHz Commodore 64
A transformer model with approximately 25,000 parameters is implemented on an unmodified Commodore 64, utilizing hand-written 6502/6510 assembly. This 2-layer decoder-only architecture features real multi-head causal self-attention, softmax, and RMSNorm, and can be loaded from a floppy disk.
github.com
5 min
4/21/2026
Building a Minimal Transformer for 10-digit Addition
A minimal transformer model has been developed to perform 10-digit addition tasks. The model demonstrates the ability to learn and execute arithmetic operations effectively.
alexlitzenberger.com
1 min
2/28/2026
Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Self-attention mechanisms in Transformers typically incur costs that increase with context length, leading to higher demands for storage, compute, and energy. A new method using symmetry-aware Taylor approximation aims to maintain constant cost per token for self-attention, potentially alleviating these resource demands.
arxiv.org
2 min
2/4/2026
Kimi K2.7-Code: open-source coding model with better token efficiency
moonshotai/Kimi-K2.7-Code can be utilized with libraries like Transformers for image-text-to-text tasks. A high-level pipeline can be created using the command `pipe = pipeline("image-text-to-text", model="moonshotai/Kimi-K2.7-Code", trust_remote_code=True)`.
huggingface.co
9 min
6/12/2026
Soul Player C64 – A real transformer running on a 1 MHz Commodore 64
A transformer model with approximately 25,000 parameters is implemented on an unmodified Commodore 64, utilizing hand-written 6502/6510 assembly. This 2-layer decoder-only architecture features real multi-head causal self-attention, softmax, and RMSNorm, and can be loaded from a floppy disk.
github.com
5 min
4/21/2026
FORTH? Really!?
FORTH and associative/applicative languages may be more suitable for transformer architectures than traditional top-down problem-solving methods. Generating outputs before their constituent parts could enhance the effectiveness of large language models.
rescrv.net
3 min
2/6/2026
Transformers Are Inherently Succinct
Transformers exhibit inherent succinctness in their representations, enabling efficient processing of information. This research has been recognized as one of three outstanding papers for ICLR 2026.
openreview.net
1 min
6/5/2026
Attention Residuals
Attention Residuals (AttnRes) serves as a drop-in replacement for standard residual connections in Transformers, allowing each layer to selectively aggregate earlier representations. It includes two variants: Full AttnRes, where each layer attends over all previous outputs, and Block AttnRes, which groups layers into blocks to reduce memory usage from O(Ld) to O(Nd).
github.com
3 min
3/21/2026
Attention at Constant Cost per Token via Symmetry-Aware Taylor Approximation
Self-attention mechanisms in Transformers typically incur costs that increase with context length, leading to higher demands for storage, compute, and energy. A new method using symmetry-aware Taylor approximation aims to maintain constant cost per token for self-attention, potentially alleviating these resource demands.
arxiv.org
2 min
2/4/2026
Do transformers need three projections? Systematic study of QKV variants
Transformers utilize a query, key, and value (QKV) attention formulation that is crucial for AI tasks. The study investigates the individual contributions of these three projections and the effects of omitting any of them.
arxiv.org
2 min
6/4/2026
Building a Minimal Transformer for 10-digit Addition
A minimal transformer model has been developed to perform 10-digit addition tasks. The model demonstrates the ability to learn and execute arithmetic operations effectively.
alexlitzenberger.com
1 min
2/28/2026
David Patterson: Challenges and Research Directions for LLM Inference Hardware
Large Language Model (LLM) inference faces significant challenges primarily related to memory and interconnect issues rather than compute power. The autoregressive Decode phase of Transformer models distinguishes LLM inference from training, complicating the process.
arxiv.org
2 min
1/25/2026
No more articles to load