Introspective Diffusion Language Models
introspective-diffusion.github.io
April 14, 2026
4 min read
🔥🔥🔥🔥🔥
61/100
Summary
Diffusion language models (DLMs) enable parallel token generation, potentially overcoming the sequential limitations of autoregressive (AR) decoding. However, DLMs currently underperform AR models in quality due to a lack of introspective consistency, where AR models align with their generated outputs.
Key Takeaways
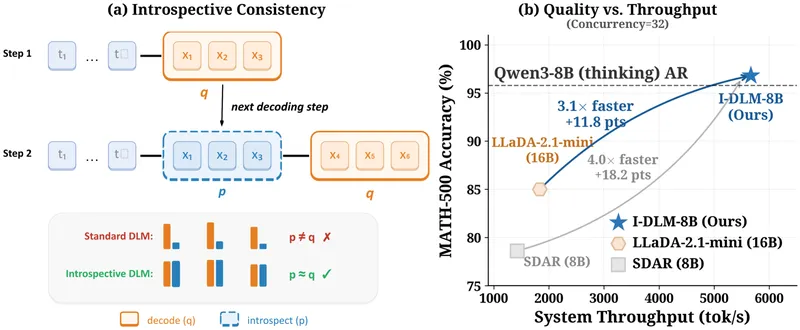
- The Introspective Diffusion Language Model (I-DLM) achieves the same quality as autoregressive models while outperforming previous diffusion language models across 15 benchmarks.
- I-DLM-8B outperforms LLaDA-2.1-mini (16B) by +26 on AIME-24 and +15 on LiveCodeBench-v6, while using half the parameters.
- Introspective strided decoding (ISD) allows I-DLM to verify previously generated tokens and generate new ones in a single forward pass, enhancing throughput by 2.9-4.1 times at high concurrency.
- Gated LoRA enables bit-for-bit lossless acceleration in the I-DLM architecture.
Community Sentiment
Positives
- Mercury 2's latency and pricing make it a compelling choice for UX experiments, enabling nearly frictionless interactions that enhance user experience.
- The transformation of a Qwen autoregressor into a diffuser showcases innovative techniques that significantly improve generation speed, making it competitive with native diffusion models.
- The ability to ground the diffuser on the base model’s distribution allows for precise output consistency, which is crucial for applications requiring reliability.
Concerns
- Challenges remain around time-to-first-token user experience and overall answer quality, indicating that improvements are still needed for broader adoption.
- There is skepticism about the practicality of comparing outputs against the base model without actually generating from it, raising questions about the methodology.
Related Articles
DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
Apr 25, 2026

Unsloth GLM-5.2 – How to Run Locally
Jun 22, 2026

LLM Architecture Gallery
Mar 15, 2026

LLM Neuroanatomy II: Modern LLM Hacking and Hints of a Universal Language?
Mar 24, 2026
Liquid AI reveals 8B-A1B MoE trained on 38T
May 29, 2026